奈良県立医科大学 保健統計学I2024
(医学部看護学科)
2024年度開講にあたって
https://medbb.net/education/2024init/
困った時,オンラインでのサポートやなにかありましたら以下からご連絡ください
私へ連絡・オンラインオフィスアワー予約
課題の提出状況については,出欠システムのところで表示するようにします.
9/1の1時限目 1回目の授業の課題
9/2の1時限目 2回目の授業の課題
評価は問題無しが○ ちょっと問題ありが△ 未提出が×で入力しています.それぞれ(出席)(遅刻)(欠席)と表記されると思いますがご注意ください
授業への出席は開講期間の部分でご確認ください 開講期間外の9月分はあくまでも上記のように課題の提出状況を示していますので勘違いされない様よろしくお願いします
なお,例年例題について回答が欲しいという声があるのですが,授業中に示したとおりですのであらためて掲載はしておりません.
課題提出フォーム
https://forms.gle/q8Fs1Ff9ZURUvE1DA授業メニュー
第01回 記述統計(1)尺度とデータ形式,度数分布,ヒストグラム第02回 記述統計(2)代表値・散布度・箱ひげ図
第03回 推測統計(1)点推定(平均)
第04回 推測統計(2)点推定(分散)
第05回 推測統計(3)平均値の区間推定(1)(標準誤差)
第06回 推測統計(4)平均値の区間推定(2)(正規分布)
第07回 推測統計(5)平均値の区間推定(3)(t分布)
第08回 まとめ
第01回 記述統計(1)尺度・度数分布・ヒストグラム
教科書12章A1~5,14章A1
記述統計と推測統計
記述統計とは
・収集したデータを要約してその集団の状況を表す・そこにあるデータは全体(母集団)
・度数(分布)・代表値・散布度・相関係数など
推測統計とは
事象の起こる確率を仮定した上で全体(過去・現在だけではなく未来も含む)を推測する。推定と検定に分類される。推定とは
・収集したデータを基にしてその集団の状況を表す・そこにあるデータは一部(標本)
・点推定・区間推定・モデリング
検定とは
・収集したデータを基にしてその集団の状況を仮定に従ってyes/Noで判断する・そこにあるデータは一部(標本)
・t検定・カイ二乗検定など
尺度
ものさし の 話ではなく 対象とするデータの特性について分類したものデータ
一般にはデータ,情報,知識などまとめて「情報」と呼ばれるケースが多い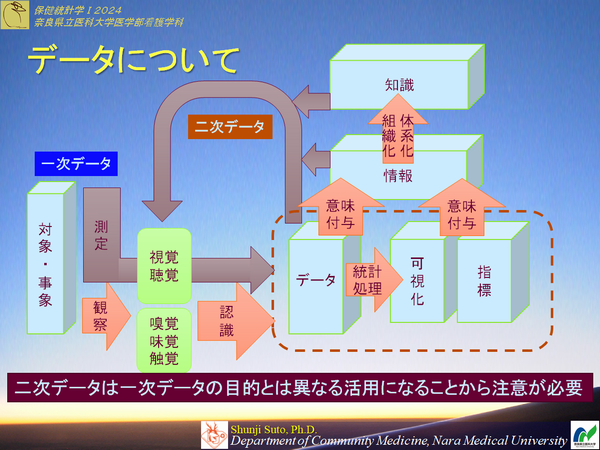
データに意味を付与することで情報となるが,騙されたりして不適切な意味を付与してしまうと大変なことになる
情報が知識構造体に取り込まれれば,そのものが大きく複雑なものになっていく.
無論知識においても,不適切な意味を付与された情報が基となっているとややこしいことになる.
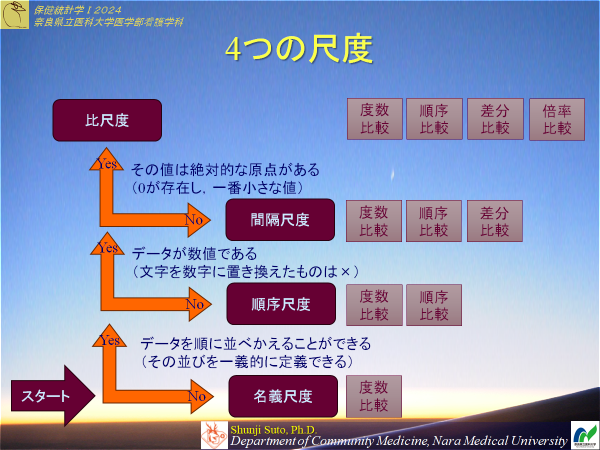
4つの尺度
世の中のデータを4つの種類で説明できる1名義尺度
2順序尺度
3間隔尺度
4比尺度(比例)(比率)
1,2を質的変量(定性的)ともいう
3,4を量的変量(定量的)ともいう
性質としては上位互換性があり
4>3>2>1
間隔尺度と比尺度との見分け方
データ自身が負の値をとることが想定されるものは間隔尺度(引き算などで便宜上マイナスになるものはデータ自身によるものではない)天気予報での摂氏温度(℃)の話をどのようにされているのか(過去に一回だけビックリしたことがあるけど)
例題1-1)
以下の文章中の下線部の尺度を示せ折角の(1)日曜日,天気も(2)晴なので車に乗って(3)イオン橿原店までドライブ.
昼食はハンバーガーチェーン店でチーズバーガーとポテトを購入,ドリンクは(4)LサイズにするかMサイズにするかで悩む
昼食後車を走らせるがガソリンが少ないので(5)35リットルほど給油.
無事目的地に到着し駐車場から外に出るとなにやら(6)少し寒い,確かに気温を見ると(7)12℃と先程よりも低い
なので上着を買って帰ることにした.丁度バーゲンセールをやっている.値段は(8)3980円,(9)凄く良いものを買うことが出来ました.
度数
どのようなデータであっても度数を求めることができるしかも求めた度数は,対象としたデータの尺度に関係なく比尺度として取り扱うことができる
(度数は絶対的な原点を持っているので+-×÷全てOK)
例題1-2)
以下の40名の血液型データについて度数を求めよ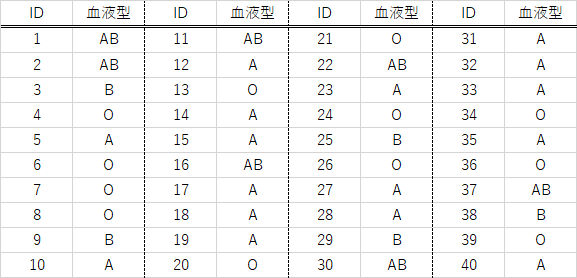
度数分布表
表にすることで,全体の状況が把握しやすくなるそれぞれのデータの度数(出現頻度)をまとめたもの
名義尺度の時は多い順(お作法として。但しその他を出すなら一番最後)
順序尺度以降であれば順(名義尺度でも比較のためにお作法を破ることはある)
度数 ・・・出現頻度
相対度数・・・総出現頻度を1(100%)としたときのそのぞれの度数のしめる割合
| (名称) | 度数 | 相対度数 |
|---|---|---|
| 計 | 1.00 |
例題1-3)
例題1-2)で求めた血液型別度数より度数分布表を作成せよ量的変量の度数分布表の注意点
例えば身長を0.1cm単位で測定して度数分布表を作成しようとしたとき,全て度数は1で全体の状況の把握が出来ないケースがあるその場合ある程度の区間を設けて度数を求める
量的変数の場合はその数値だけで度数を積み上げようにもなかなか上手くいかない場合がある.
|
「A~B」は「A以上B未満」と読む格好がスタンダードと思っていますが,分野などによって違うようです 「A以上B以下」のようにどちらの階級にも属してしまう可能性のある設定はしないように. |
| 階級 | 階級値 | 度数 | 相対度数 |
|---|---|---|---|
| 130~140 | 135 | ||
| 140~150 | 145 | ||
| 150~160 | 155 | ||
| 160~170 | 165 | ||
| 170~180 | 175 | ||
| 計 |
例題1-4)
あるクラスの生徒の身長を計測したところ以下のような結果が得られた.度数分布表を作成せよ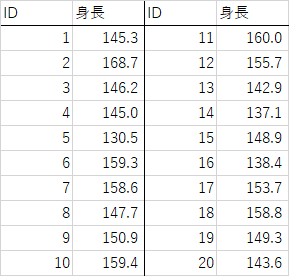
度数分布図
度数分布表を棒グラフにしたもの質的変数
縦棒グラフ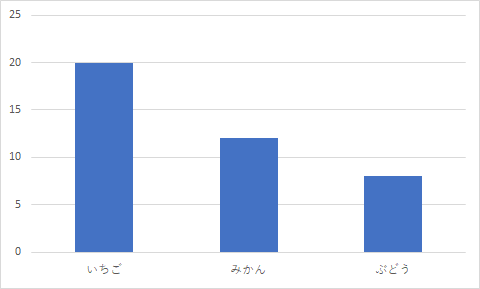
量的変数
ヒストグラム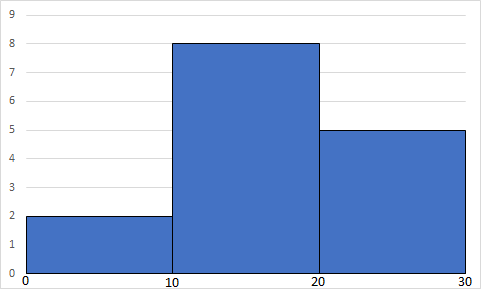
棒の間隔が無いのは値が連続している状態であるが故
普通の棒グラフは棒の長さが度数を示すが,ヒストグラムは棒の面積が度数を示す
| 「階級の幅を等しくすること」と説明している場合があるが,それは幅が変わると高さが変わる故で,実際にはそのような区間設定はよくある |
|
ヒストグラムーなるほど統計学園(総務省統計局) https://www.stat.go.jp/naruhodo/4_graph/shokyu/histogram.html |
課題
本日の授業を受講したうえで,以下の2つの質問1.理解できた内容,理解できなかった内容について
2.本日の授業の内容に関する質問(内容が概ね理解できているのであれば空欄でも可です)
を締切までに提出の事
締切は授業日
課題の感想等
概ね理解できたが順序尺度の解釈が難しいというところでした尺度は例を交えながらというところが良かったとのこのですが,教科書だと変数を示しているだけなので文章にしたほうが考える機会になればと
尺度の話は若干腑に落ちない方がある程度おられるので以下追記
全ての変数(摂氏温度(℃),重さ(kg)は少なくとも名義尺度の性質は有している.
そこから順序尺度の性質を有しているのかという恰好で,一般的に最上位の尺度で表現されている.(順序尺度だけど名義尺度の性質を有しているので,その性質を利用する文脈で名義尺度と表現しているケースもある)
天気の話は,晴と雨の軸で 快晴-晴-曇-小雨-弱い雨-やや強い雨-強い雨-激しい雨-非常に激しい雨-猛烈な雨
尺度の話は,関心のあるデータを取り扱うときにどのような性質を有していて,目的に応じてどの性質を選択して統計処理するのかというところでしょうか.
故に目的や状況に応じて適切なデータの取得とともに,取りまとめ方についても考えなくてはいけない格好になります
<参考>晴れと曇りはどう区別するのですか?(横浜地方気象台)
https://www.data.jma.go.jp/yokohama/shosai/03-about/02-annai/01-qa.html
<参考>雨に関する用語(国土交通省気象庁)
https://www.jma.go.jp/jma/kishou/know/yougo_hp/kousui.html
第02回 記述統計(2)代表値・散布度・箱ひげ図
教科書12章D,14章A2(来年のシラバスでは直しておきます)
量的変量の統計量
度数は質的変量でも算出可能だが,今回の話は量的変量のみの話ただし,量的変量は質的変量の性質も持っているので,その性質を利用している統計量もあります.
代表値
average(その集団でとりまとめたデータを数値一つで表す。excelはaverage関数で算術平均を出すが、代表値の代表ということだからと解釈しています)平均
算術平均
mean(算術平均以外にも相乗平均などもあります)1/n・Σxi
パレートの法則(80-20の法則)
代表値なのに実在しない場合がある → 集団の指標(重心)であって、事象を代表する値そのものを示しているとは限らない
幾何平均(相乗平均)
全て掛け合わせて累乗根をとる例えば1と2と4の平均
算術平均 (1+2+4)/3=2.3333
幾何平均 3√(1×2×4)=2
加重平均
重みづけ平均例えば ミニテストと期末試験の平均をとる → そのままの平均で良いの?
度数分布表を用いた平均もこの方法・・・Σ(階級値×階級の度数)/n
例題2-1)
あるクラスの生徒の身長を計測したところ以下のような結果が得られたa)この集団の算術平均を求めよ
b)先週作成した同データの度数分布表から集団の平均値を求めよ
c)もしできるならこの集団の幾何平均を求めよ
中央値
median(別名第2四分位数)量的変量を順序尺度の性質で処理した代表値
順番に並べたとき真ん中の順位にきた個体の値
個体数が偶数の時は真ん中2つの数値の平均値
最頻値
mode(流行,はやり)違う意味で数の理論(多数決)の世界
量的変量を名義尺度の性質で処理した代表値
名義尺度でわかることは一緒か違うか
階級毎に度数をカウント
一番多いところの階級値
一位が同点の時は併記
平均値と中央値の考え方の違い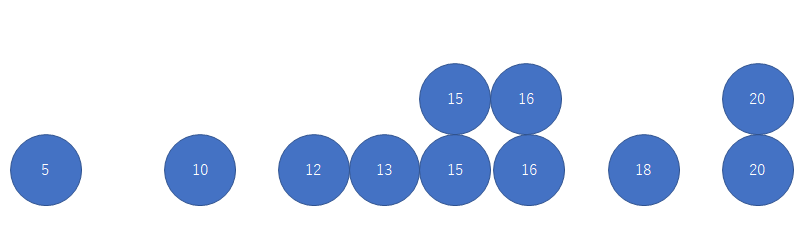 平均値(14.55) 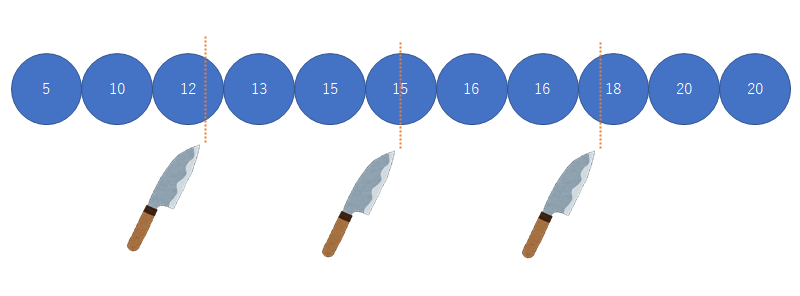 こちらは分布なんて関係なく中央値(15) データの分布に依存する(パラメトリック)=平均値 と データの分布に依存しない(ノンパラメトリック)=中央値,最頻値の関係がわかるかなと思います 例えば5が0に変わってしまうと平均値は大きく変わりますが,中央値は変わりません パラメトリック・・・数値に依存する(数値の分布によって値が影響を受ける)というとイメージしやすいのかな? |
例題2-2)
あるクラスの生徒の身長についてa)この集団の中央値を求めよ
b)この集団の最頻値を先週作成した度数分布表から求めよ
散布度
dispersion範囲
ある値~ある値までの広さ範囲
RangeR=最大値-最小値
特徴
外れ値もひらう
算出が用意
最大値と最小値がわかればその集団のバラツキがわかる
最大値maximum excel max関数
最小値minimum excel min関数
四分位範囲
小さい順(昇順)に並べて集団を4分割分割する所の値を小さい方から第1四分位数(Q1),第2四分位数(Q2)=中央値,第3四分位数(Q3) 四分位範囲IQR(interquartile range)=Q3-Q1
四分位数の話
四分位数は出し方が何種類かあります.近年は高校で教育されていますがその方法も従来のものと異なるので細かい計算をするのはやめておきますパーセンタイルの話
第1四分位数は25%タイル値,第2四分位数は50%タイル値,第3四分位数は75%タイル値のことです.混乱しがちなのは第一四分位数が小さい方から数えてなのに,大きい方から数える人がいます
その時はパーセンタイルで整理したほうが良いかもしれません(100%=最大値)というのは納得できると思うので上から75%=第3四分位数
箱ひげ図
四分位範囲をグラフ化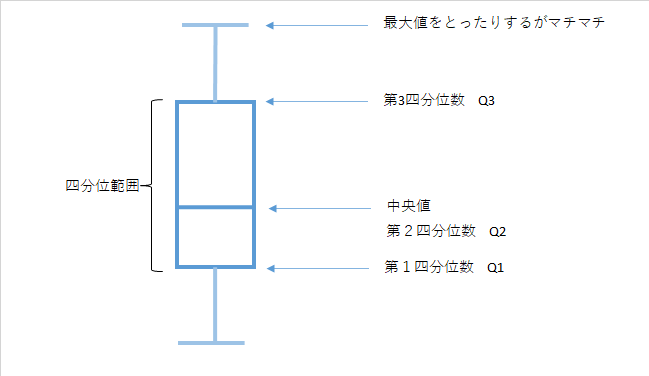
偏差
Deviationある基準とする値からのズレ
それぞれのズレの平均を求めたら良いのだろう・・・
分散
varianceexcel関数はVAR
偏差を平方(二乗)したものの平均
ここでは記号をσ^2とする. Σ(Xi-Xbar)^2/n
何故平方するの?
どうしても偏差の平均を求めることが出来ないので
標準偏差
Standard Deviation記号はσ
σ=√(σ^2)
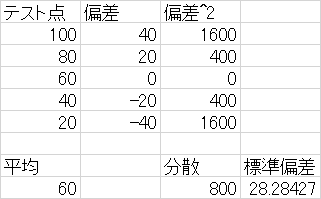
例題2-3)
以下の表について| ID | テストの点 |
|---|---|
| 1 | 40 |
| 2 | 40 |
| 3 | 80 |
| 4 | 60 |
| 5 | 30 |
b)この集団の標準偏差を求めよ
c)この集団の範囲を求めよ
d)この集団の中央値を求めよMbr>
課題
本日の授業を受講したうえで,以下の2つの質問1.理解できた内容,理解できなかった内容について
2.本日の授業の内容に関する質問(内容が概ね理解できているのであれば空欄でも可です)
を締切までに提出の事
締切は授業日翌日朝10時までとする
課題に関するコメントなど
概ね高校数学の復習という形だったので躓いている方はいなかったように思います.なんとか記憶を取り戻した系の方もおられたように思うので,良かったというところです
次週から「推定」の話になりますが同じようで違う話にあってきますので注意深く理解するようにして下さい
標準偏差が何を表しているのかが分からないです。
それぞれの値の平均値との偏差(個々のバラツキ)の平均となります.平方根にする方法、電卓を使わなければ出来なかったので電卓を使わないで求められるなら
素因数分解してまとめると,ある程度のレベルであれば計算は可能かなと思っています.例えば分散が450だった場合 2×3×3×5×5 になります.
√450=√(2×3×3×5×5)=3×5√2
√2=1.4142 ですので 15×1.4142=21.213 となります.
最頻値,もし4階級の度数が同じ場合でも並列で記載でよい?
よいです.度数分布表の階級値で、例えば1番上を130~140で説明してたが私は130.0~139.9としたけど
量的変量の度数分布表はカバーできていない部分や,重複している部分が出てくると辻褄が合わなくなります.年齢の階級別で0~9 10~19 のように10以上19以下と読む格好で作成されているものがありますが,年齢は少数を切り捨てして整数化したものなので成立していますが
身長の場合は連続量で単位にそのような取り決めが存在しないので,そのまま連続量として階級を設定するので 10以上20未満のように前の階級と連続させるようにします.
ご質問の場合だと 130.9999はどのような取り扱いにするのか悩むというところでしょうか?
質問の本筋は階級値の話だったのですが,その方の場合階級値は(130+139.9)/2=134.95となるから云々とのことでした.
140未満とすると厳密には139.99999・・・・・・・ となるので ≒140として階級値を求めている格好です.
<参考>
明治三十五年法律第五十号(年齢計算ニ関スル法律)(e-gov)
https://elaws.e-gov.go.jp/document?lawid=135AC1000000050
暦による期間の計算 民法(明治二十九年法律第八十九号)第百四十三条(e-gov)
https://elaws.e-gov.go.jp/document?lawid=129AC0000000089#Mp-At_143
第03回 推測統計(1)点推定(平均)
教科書13章B1
記述統計では,対象とする集団そのものを可視化することが目的でした
推測統計では,対象とする集団は全体の中の一部(サンプル)という捉え方で,サンプルから全体像を推し測ることを目的としています
これまでの授業の中でも記号が出てきていますがここでまとめておこうと思います
記号について
推定の話になると記号の取り扱いで混乱するのでここで整理しておきます.分かりやすさを優先して整理したので,皆さんの使っている教科書などの表記は<参考>の論文を確認し読み替えください
μ・・・集団全体(母集団)の算術平均=母平均
σ^2・・・集団全体(母集団)の分散=母分散
σ・・・集団全体(母集団)の標準偏差=母標準偏差
xbar・・・集団の一部(標本)の算術平均=標本平均=母平均の不偏推定量
s^2・・・集団の一部(標本)より求めた母集団の分散の推定量=不偏分散(母分散の不偏推定量)
s・・・集団の一部(標本)より求めた不偏分散よりもとめた標準偏差=母標準偏差の推定量

参考
統計学テキストの「分散」の表記に関する調査(札幌学院大学総合研究所紀要 巻 1, p. 1-10, 発行日 2014-03-31)https://sgul.repo.nii.ac.jp/records/1807
母集団と標本
母集団
対象としている集団の全体のこと無限母集団と有限母集団がある
標本
対象としている集団の一部偏ってしまうことに注意
例)森で取れた昆虫の標本を作成する際、どうしても森全体の昆虫の分布から偏ってしまう
取り扱う標本について
母集団は20000人の収縮期血圧データ(整数)母集団のヒストグラム
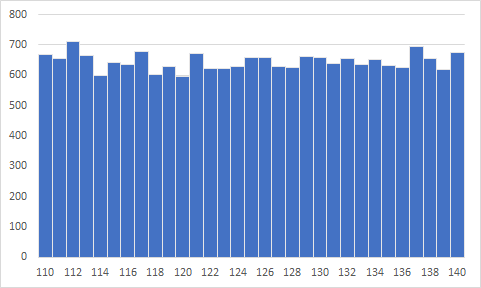
その集団の一部を抽出したものが標本
母平均の推定
得られた標本より求めた平均をそのまま母集団の推定値とする例題3-1)
以下の標本より母集団の平均値(母平均)を推定せよ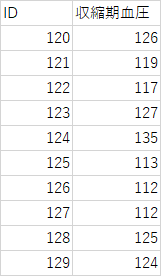
利点
計算が容易平均値の場合,計算式が母集団全体の値を求める時と標本から推定する時と同じで良い
欠点
必ずしも推定値が実際と一致するわけではない・・・むしろ外れて当然サンプルサイズ10の時(母集団から2000の標本が作成できる)のヒストグラム
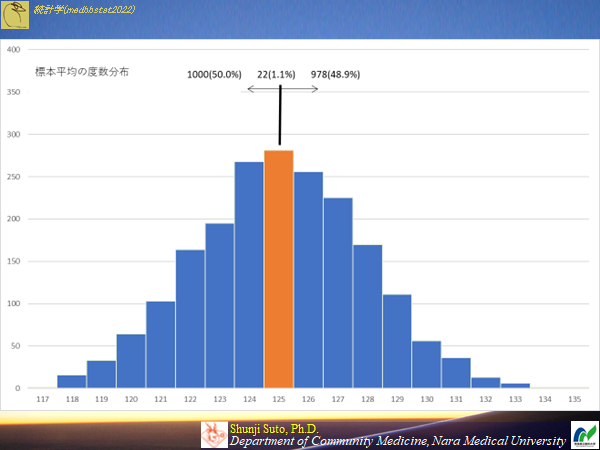
ピッタシ一致するのはサンプルサイズ10の時で1.1%(98.9%はハズレ)
まとめると
推定で求められるのは偏った推定にならないこと.(なぜならほぼ一致しないから)・標本が偏っていたら推定値は偏る
×標本が偏っていなくても計算によって推定値が偏る
前者はサンプルの集め方の話なので,計算そのものに問題があるわけではない
後者に問題があると・・・・
推定の精度を上げるためには

標本数を大きくすればよい・・・測定を繰り返して行いその平均をとると精度は上がる
サンプルサイズを100にした時の(母集団から200の標本が作成できる)のヒストグラム
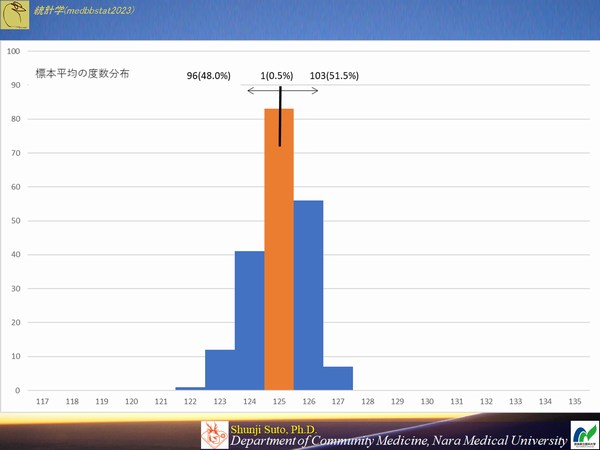
精度は上がるものの,ピッタシ一致する確率も上がるとは限らない
例題3-2)
例題3-1)のデータと例題3-1)で求めた母平均の推定値との偏差を求め,偏差和(全て足し合わすこと)を求めよ.そして偏差平方和も求めよ例題3-1)のデータと私だけが知っている母平均(125.0)との偏差を求め,偏差和を求めよ.そして偏差平方和も求め,それぞれ比較せよ
課題
本日の授業を受講したうえで,以下の2つの質問1.理解できた内容,理解できなかった内容について
2.本日の授業の内容に関する質問(内容が概ね理解できているのであれば空欄でも可です)
を締切までに提出の事
締切は授業日翌日朝10時までとする
課題に関するコメントなど
推定の平均と母平均とでは軸がズレるためばらつきの大きさが変わるということがわかった。
今回、授業中に解いた問題は先生の話や友達と話し合って理解することができた。
推定値は一致することはないということを学びました。その中で、推定値をより正確な値に近づけるためには標本数を増やせば良いといことを学びました。例題の偏差を求めてみて、0にならなかったことから、推定値は正確でないということがよくわかりました。
ありがとうございました.時間をかけて理解できた方もおられたので,良かったと思います友人と話し合いしながら進める利点が出たように思います.皆さんが授業の内容を基に話し合いをしたからこその効果に思います.感謝します
私だけが知っている平均値とはどういう概念のものなのか
本来推定する場合は,母集団全体を把握していない中で行うので,「誰も知らない」としたいのですが,そうすると母平均を提示できないので第04回 推測統計(2)点推定(分散)
教科書13章B1
母分散の推定
例題4-1
以下の標本から分散を求めよ点推定
先程の例題で算出した値で母集団の特性値(母数)の推定はしていいのだろうかまとめると(再掲)
推定で求められるのは偏った推定にならないこと.(なぜならほぼ一致しないから)・標本が偏っていたら推定値は偏る
×標本が偏っていなくても計算によって推定値が偏る
前者はサンプルの集め方の話なので,計算そのものに問題があるわけではない
後者に問題があると・・・・
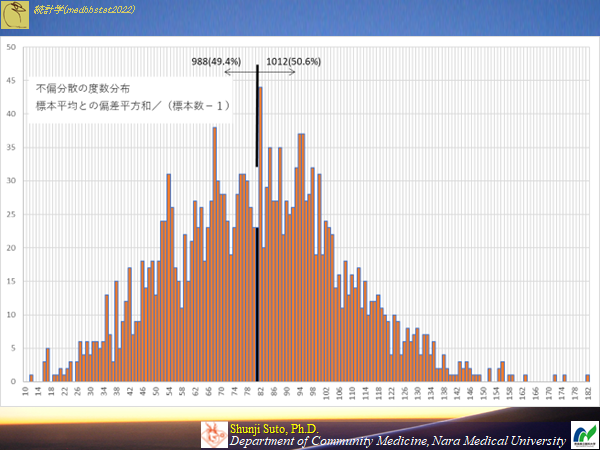
標本の平均を用いサンプルサイズ10の時(母集団から2000の標本が作成できる)のヒストグラム
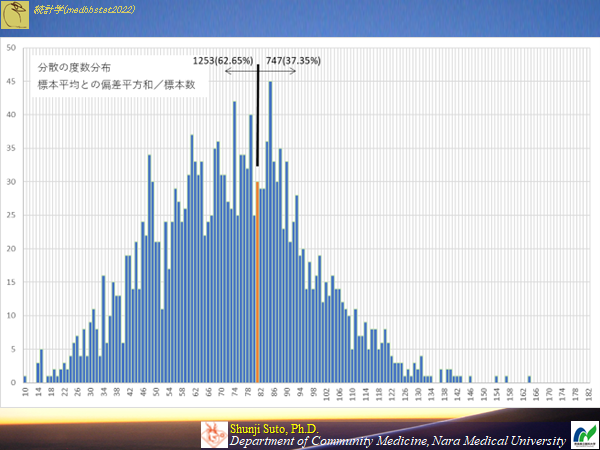
低めの値が多くなる傾向で偏っている.
母集団の平均(本来知る由もない)を用いサンプルサイズ10の時(母集団から2000の標本が作成できる)のヒストグラム
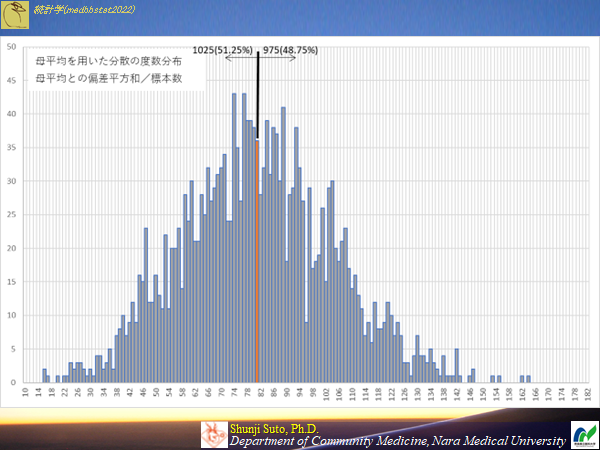
偏った推定にならないものの,本来知る由もない母平均を使えるわけがない(そもそも母数知っているなら推定は不要でしょう)
不偏分散
標本の平均を用いて母分散の推定を行う.母平均と標本平均は(ほぼ)異なるので,母平均と標本平均の差も考慮して分散を求めたもの
(無論母平均は分からないが母平均と標本平均の差を考慮している)
s^2=Σ(Xi-Xbar)^2/(n-1)
nで除するよりn-1で除したほうが,値が大きくなるのは当然なので,低めの値が出るのなら少し分母を小さくした方が大きくなるのは理解できるが(ケーキを3人で分けるのか4人で分けるのか)なぜ1引くだけ??となると思います
<参考>
不偏分散は何故nではなく(n-1)で除するのか(生物統計学2018奈良医大)
https://medbb.net/education/nmubiostat2018/index.html#VAR
例題4-2
以下の標本より母集団全体の平均値および分散と標準偏差の推定値を求めよ母集団の平均の推定値(つまり標本の平均)を用いて母標準偏差の推定値(不偏分散の正の平方根)を幅にすればとりあえず100%ではないなにかしらの区間で推定が出来た
一方,標本数が増えると標本平均の分布は狭まることは確認している.果たして不偏分散は標本数が増えるとどのような挙動になるのだろう
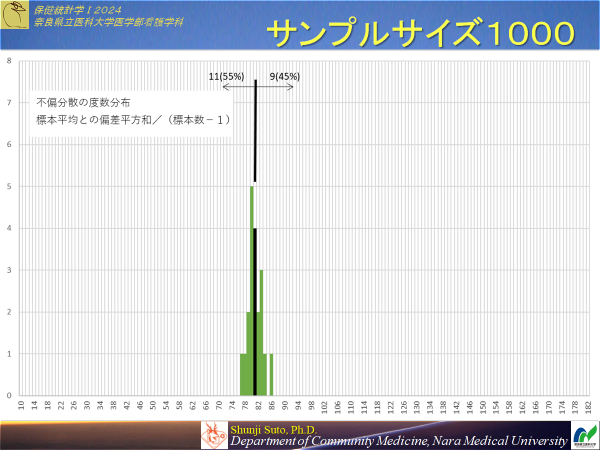
と,サンプルサイズを10→1000に増やすと不偏分散の分布の幅は狭くなったものの,推定値そのものは変わっているわけではない・・・
課題
本日の授業を受講したうえで,以下の2つの質問1.理解できた内容,理解できなかった内容について
2.本日の授業の内容に関する質問(内容が概ね理解できているのであれば空欄でも可です)
を締切までに提出の事
締切は授業日翌日朝10時までとする
課題に関するコメントなど
標本平均は母平均の推定量ですか?不偏分散は母分散の推定量ですか?その通りです.偏らない推定(不偏推定量)n/(n-1)を標本の分散にかけると不偏分散になるのには驚きました。また、先週の講義内容を1週間で考え直してみたのですが、標本の偏差が母集団の偏差より小さく出る理由は、標本は母集団に比べて範囲が小さいからだと考えました。ありがとうございます.たしかに標本は母集団に比べて範囲が小さくなる可能性は高い(有限母集団ならば標本の範囲は母集団の範囲以下になるので)ですが偏差の話は基準を標本の平均値にすると偏差平方和は最小になるという話です
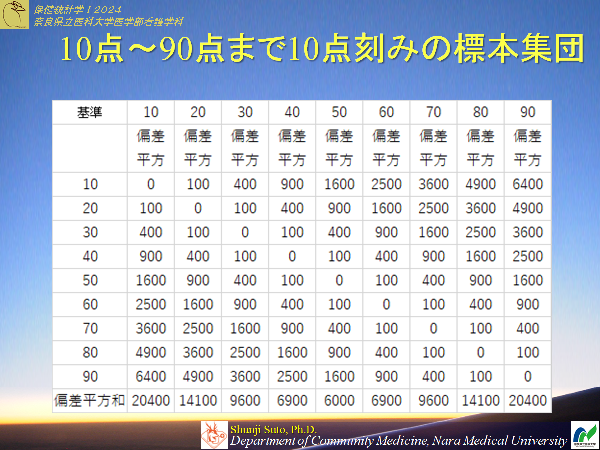
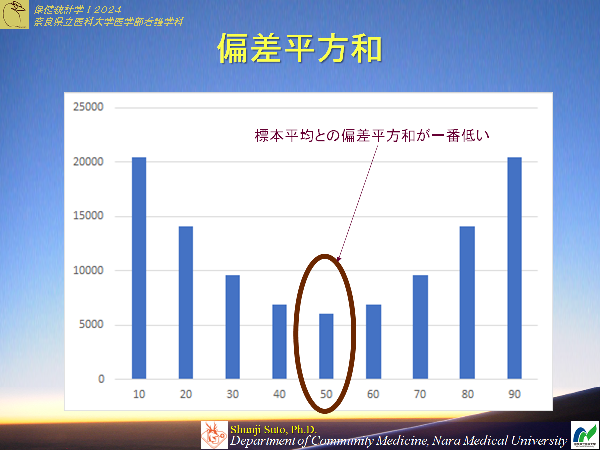
不偏分散でマイナス 1するのは、不偏分散は母分散よりも小さくなる性質に由来することを学んだその通りで以下のようになります
計算の仕方がわかったが、n-1をなぜ使うのか分からない。
なぜn+1ではだめなのかということです。
母平均が標本平均より低い値が出た時はn-1で理解できるのですが、その逆の場合は、n+1にならないことが理解できませんでした。
母平均を知る由は本来無いので,標本平均が大きいから,小さいから という条件で計算式が変わることはありません.nで割ると母分散よりも小さくなってしまう確率が高くなるからという説明でいかがでしょうか
第05回 推測統計(3)平均値の区間推定(1)(標準誤差)
教科書13章B1
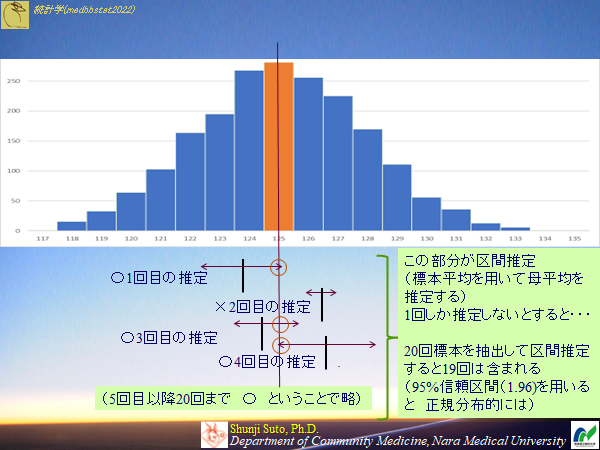
点推定の欠点・・・母平均や母分散など母数をピッタリ当てることはほぼほぼ無理.区間で推定すれば,その気になれば100%の確率で当てることは可能
例題5-1
ある高等学校の3年生生のうちあるクラスの生徒40人にアンケートを取り,お小遣いを親からいくらもらっているのか調査したその結果の算術平均をとると6500円だった.
はたしてその高校の3年生全体のお小遣いの平均はいくらになるだろうか?100%当たるよう下限の金額と上限の金額を示せ
区間推定
点推定に幅をもたせたもの.幅の定義は確率(どの程度あたるものか)
∴100%あたる推定に意味は無い→確実に当たる幅を設定したら達成できるので
一般的に95%の確率で当たる区間(95%の信頼区間)で幅を決めている
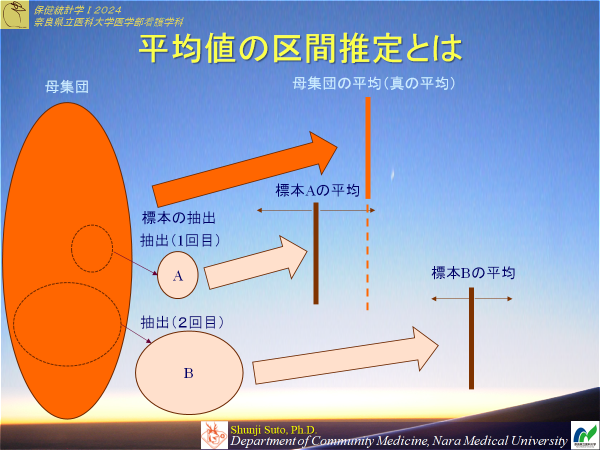
平均値の区間推定
母平均の点推定値(=標本平均)を中心に母分散の点推定値(=標本から求めた不偏分散)をベースに幅を持たせる.例題5-2
標本平均はサンプルサイズが大きくなるとどうなりますか?標準誤差
・標準偏差は標本の分布のバラツキ具合を示したもの・標準誤差は母集団から抽出した標本の平均値のバラツキ具合
SE=σ/√n
ここでは,なぜ√nになるのか説明しないが,少なくともサンプルサイズが大きいほど標本平均のバラツキ具合が小さくなっていくことは理解できると思う
どうしても という方は以下のリンクご覧ください.
<参考>標準誤差SEはなぜ標準偏差σを√nで除するのか(生物統計学2018奈良医大)
https://medbb.net/education/nmubiostat2018/index.html#SE
例題5-3
以下の標本から標準誤差を求めよ平均値の区間推定のイメージ
例題5-4
サンプルサイズ10000で求めた標本の平均が110,不偏分散が400だった時の標準誤差を求めよ課題
本日の授業を受講したうえで,以下の2つの質問1.理解できた内容,理解できなかった内容について
2.本日の授業の内容に関する質問(内容が概ね理解できているのであれば空欄でも可です)
を締切までに提出の事
締切は授業日翌日朝10時までとする
課題に対するコメントなど
概ね理解できたという声が多く良かったと思っています.授業が進むにつれて、習ったことがつかながってきて少し難しい今は皆さん同じ内容を学修してますが,いずれ皆さんはそれぞれ異なる問題に向き合うのでベースとなる知識をしっかりとしたものにしてください
サンプルサイズが大きくなると標本平均のバラツキ具合が小さくなっていくのが初めイメージ出来なかった通常みなさんは一つの標本に対して平均値を求めるのが精いっぱいなので,同じことを何回もするというのは経験しにくいところで
例題5-2を解き、nー1の理由を理解できた例題5-4ですかね.ラウンドしていて,不偏分散を与えているのでそのまま計算すればいのになぜか分散(標本の)を割り戻している方がおられました.そこから標準誤差を求めていたので??でしたが,丁寧に説明すると理解いただけたように思います.そこではどちらも似たような値になっていたのですがサンプルサイズが大きかったので似たような値になりましたが,その意味も理解いただけたと思います
答えは求められるが何故そうなるのかの理解が難しい.もう少し前の範囲からやり直す必要があると感じている.式を覚えるだけでは理解になっていないのでもう少し理解を深めたい仰る通りで,導き出すところまで出来たから次のステップに向かっておられるところに思います.導き出すところで止まるとそこから先の成長は見込めません.コンピュータでさえ数式さえ入力すれば導き出すことはできます.そこから先が重要な部分になります.
標準誤差が「母集団から抽出した標本の平均値のバラツキ具合」という言葉の意味が理解できない
母集団から抽出した値(=サンプルサイズ1で抽出した標本の平均)のヒストグラム(→標準偏差)
母集団からサンプルサイズ10で抽出した標本の平均のヒストグラム(→平均値の標準偏差=標準誤差)
母集団からサンプルサイズ100で抽出した標本の平均のヒストグラム(→平均値の標準偏差=標準誤差)
第06回 推測統計(4)平均値の区間推定(2)(正規分布)
教科書12章C1,13章B1
正規分布
左右対称の釣鐘状分布平均値に近いほど出現率が高く遠ざかるに従って低くなる(ことが多い)
同じ事柄を同じ条件で繰り返すと正規分布になるという話→中心極限定理
中心極限定理
サンプル数が多ければ標本平均の分布は正規分布になる→正しく測定されているのであれば偶然誤差の発生は正規分布に従う
→測定回数を増やせば増やすほど
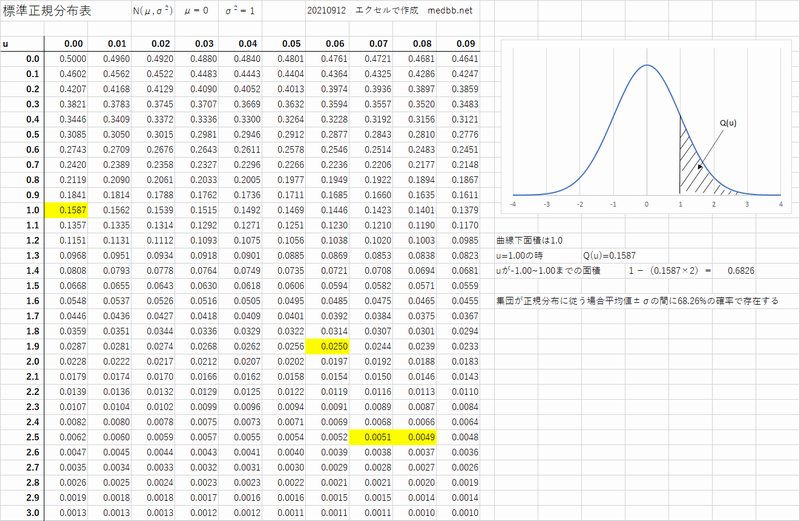
標準正規分布
平均値が0標準偏差=1(分散も1)になるように値を変換したものそれをZ値という・・・標準正規分布表の行と列から求める値の事
偏差値は平均値を50、標準偏差=10になるように値を変換したもの
それを偏差値という
例題6-1
平均値が75点の集団がある.標準偏差は5点.そこで82点を取った人がいる.その時のZ値および偏差値を求めよ
標準正規分布表
標準正規分布表のPDF版はコチラから
例題6-2
あるテストを受けたところ偏差値は65と言われた.受験者が10000人とした場合,受験者の得点の分布が正規分布に従うとしたら,順位は?例題6-3
あるテスト(受験者が10000人)を受けたところ87点だった.平均点は73点標準偏差は3.5点だった.受験者の得点の分布が正規分布に従うとしたら,順位は?例題6-4
あるテスト(受験者が全員で100000人)でその中の10000人の平均点を調べたところ73点標準偏差(不偏分散に基づく)は3.5点だった.受験者の得点の分布が正規分布に従うとしたとき,平均点(73点)を中心に95%の確率で母集団全体の平均が含まれる得点の範囲を示せ標本を基に母集団の平均(母平均)を95%信頼区間で求める
ある試験の受験者100人から点を教えてもらったところ平均値(点推定)=65点であった.なお母標準偏差は=18点であることがわかっている.受験者全員(=母集団)の平均値の区間推定を信頼区間95%で示せ

例題6-5
あるテストを受けた.受験者全員の平均点を推定したい.100名の受験者に協力してもらい点数を教えてもらった.100名の受験者の平均点は80点,偏差平方和を求めたところ99000になった.95%信頼区間で受験者全員の平均を推定せよ
課題
本日の授業を受講したうえで,以下の2つの質問1.理解できた内容,理解できなかった内容について
2.本日の授業の内容に関する質問(内容が概ね理解できているのであれば空欄でも可です)
を締切までに提出の事
締切は授業日翌日朝10時までとする
課題について
理解できてる方が多かったありがたい 良かったです系
偏差値の求め方を式で覚えるのではなく考えて理解することができた。Z値が先に出てくるということも理解することができてすっきり本来の点数の世界、平均点0の世界、偏差値の世界で考えると分かりやすい
95パーセントを求めて何になるのか
区間推定の際に標準誤差(平均の標準偏差)が分かっている(もしくは推定できている)のであれば95%信頼区間での推定が出来ます例題6-1系
標準偏差と比較して1.4という数字をなぜ出すのか
1標準偏差分が偏差値の世界では10に相当するから,今回の得点82点と75点の差は標準偏差何倍分になるのか求めたわけで例題6-2系
順位が0.3という数字が出てきたのが理解できなかった。
設問ミスでしたもろもろ
0.0250を探した理由は、(100-95)÷2ということ?
そのとおりです標準正規分布表の使い方は理解できましたが、この表に全て入り切らないと思うので、それをどのように求めるのか
すみません,そんな問題作っちゃいました.表で無理な場合は関数から求めるのが楽です分かった気がするけど時間が経てば分からなくなると思う
復習されていると思うので大丈夫かなとテストの点数の分布に大きく偏りがあるときは、今回求めたような順位は全く役に立たないということ?母集団が正規分布と見做せない場合はその通り.ただし平均値を推定する場合は「中心極限定理」の話があるのでサンプルサイズ大であれば見做せる
例題6-6(復習というか先週出来なかったので)
あるテストを受けた.受験者全員の平均点を推定したい.100名の受験者に協力してもらい点数を教えてもらった.
100名の受験者の平均点は80点,偏差平方和を求めたところ99000になった.95%信頼区間で受験者全員の平均を推定せよ
第07回 推測統計(5)平均値の区間推定(3)(t分布)
教科書
12章C1,13章B1
t分布
母集団の平均値を推定するにおいて,標準正規分布を使うと上手くいかないケースがある・・・特に標本数が少ないと
困っていたゴセットさんが標本数によって平均値の出現する確率が変化する分布を示しました.
諸々の理由でt分布と呼ばれています.
|
酒井 弘憲,ギネスビールと統計家ペンネーム スチューデント,ファルマシア51巻12号,2015 https://www.jstage.jst.go.jp/article/faruawpsj/51/12/51_1168/_article/-char/ja |
母集団の分散(標準偏差)が既知の場合(実際にはなかなかお見掛けすることは無いが),もしくはサンプルサイズが非常に大きく標本から求めたものの母集団の分散として取り扱って差し支えないものであれば正規分布で推定しても良い
t分布は標本より求めた母標準偏差の推定値(不偏分散に基づく標準偏差)を用いるが,標本の自由度(標本数より求める)によって変化する.
故に標本数が多くなるとt分布は正規分布に近似されていく.
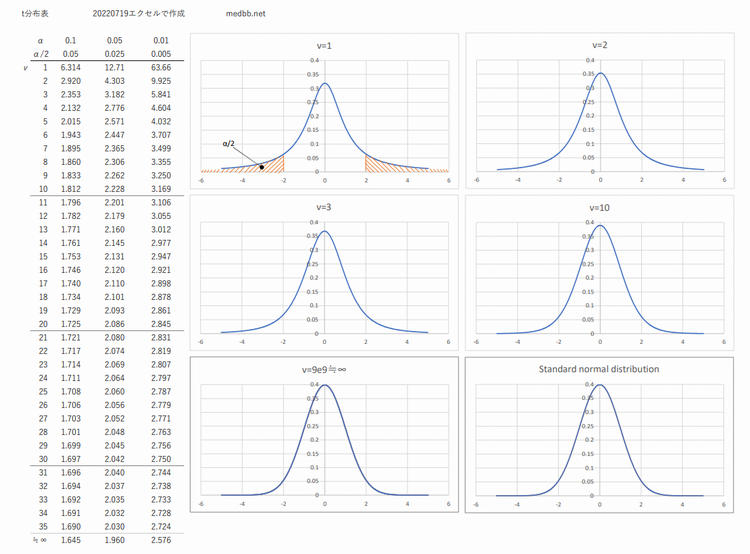
t分布のPDF版はコチラから
「自由度」νが出てきますが,以下考え方
標本の中で自由に振る舞うことが許されている値の数例えば標本から平均を求めたとき,その平均が母数の推定値としたら、自由に振る舞えない値が出てくる(つじつま合わせ)
t分布は抽出した標本数を基にしたものなので,正規分布のように一義的なものでは無く,標本数(自由度)によって確率分布が変わる
例題7-1
自由度が∞の時のt分布の95%信頼区間は正規分布と同じであるが自由度νが25の時,正規分布では何パーセント信頼区間に相当するのか?自由度が9の時も同様に求めよ
例題7-2
あるテストを受けた.受験者全員の平均点を推定したい.36名の受験者に協力してもらい点数を教えてもらった.36名の受験者の平均点は80点,偏差平方和を求めたところ15435になった.95%信頼区間で受験者全員の平均を標準正規分布とt分布でそれぞれ推定しどちらの区間幅が大きくなるか確認せよ.
課題
本日の授業を受講したうえで,以下の2つの質問1.理解できた内容,理解できなかった内容について
2.本日の授業の内容に関する質問(内容が概ね理解できているのであれば空欄でも可です)
を締切までに提出の事
締切は授業日翌日朝10時までとする
課題の感想
順調に理解いただいた方が多かったです.分からない部分を仰っている方は,その認識があるので対応が可能ですが,分からない部分がわからない方で記載されていない方もいるのだろうなと思います.
その場合,何処までの事を分かっているのか考えていただくと良いかと思います.
理解したこと
今までの授業が全て繋がった気がする
ありがとうございます標準正規分布とt分布の違い
サンプルサイズが小さいと標準正規分布から外れるので範囲を広める
自由度とは割り勘の説明でよく理解,お会計のときに割り勘をする例えがわかりやすかった
本当は割り勘が成立しない状況の話ですよね・・・わからなかったこと
t分布を使う理由
授業中に説明した通りですが・・・ゴセットさんの話分散を出す時にn-1を引く理由
第4回の内容になりますのでそちらを当時「推定値の場合はn-1を使うと更に母集団の値に近づく」と理解されていたので,振り返れば大丈夫と思います
どの授業も過去の内容の積み重ねと思うので,復習していくことで疑問を回避出来たら良いなと思います
標準正規分布95パーセント平均推定では1.96ですが、それがなに
6回目の授業振り返ってください数値の取り扱いに問題無いように思いますが正規分布が何なのか,標準正規分布はどのようなものなのか,理解が不十分故に思います
疑問質問系
自由度は35以上は∞ということ?
紙面の都合で書いていないだけです.自由度とは何 割り勘する時の具体例の考え方?
一緒な考え方になります.もう少し詳しく言うと統計量が求められている数によって自由に振舞えるn数は変わります.この授業ではn-1しか出てきませんがカイ二乗検定の時などは自由に振舞えるn数を数式で示すとn-1とならない部分もでてくるようになりますが,割り勘概念(自由にふるまえるn数)で説明できます もっとも割り勘概念は,もはや割り勘になっていない話をしているのですが・・・
<参考>
第06回FTF 推測統計(4)カイ二乗検定(奈良県立医科大学 保健統計学I2021(医学部看護学科))
https://medbb.net/education/nmuhlthstat12021/#6
ご要望系
例題とか問題とかもっと,試験に向けて練習問題の配布を
特に考えておりませんが,友人同士で問題作成されたら一石二鳥かと思います.それで許してもらえますか?第08回 まとめ
これまでの授業を振り返りながら,テストで確認する部分についてお話の中で決めていきながら,という恰好で進めようと思います.電卓は持ち込み可とします.その他資料は一切不可