大阪リハビリテーション専門学校 統計学2015
(理学療法学科)
授業について
教科書
メディカル コ・メディカルの統計学(共立出版)http://www.kyoritsu-pub.co.jp/bookdetail/9784320014862
以下のような格好で教科書を用います
O:概ね利用 △:少し利用る X:ほぼ利用しない
△1章 序説
×2章 確率
△3章 確率変数と確率分布
O4章 標本データの要約
O5章 推定・検定の基礎
O6章 推定・検定の実際(I)
X7章 推定・検定の実際(II)
△付録 標本データのもつ情報を視覚化する
大まかな進め方としては 記述統計→推測統計 の流れです。
電卓使いますのでよろしくお願いします(授業中はスマホで可ですが試験の時は×)
授業メニュー
第1回 記述統計(Ⅰ)-尺度・度数分布について
第2回 記述統計(Ⅱ)-代表値について
第3回 記述統計(Ⅲ)-散布度について
第4回 記述統計(Ⅳ)-相関係数・回帰直線
第5回 推測統計(Ⅰ)-推定
第6回 推測統計(Ⅱ)-t検定
第7回 推測統計(Ⅲ)-カイ二乗検定
第1回 記述統計(Ⅰ)-尺度・度数分布について
到達目標1-1記述統計と推測統計について説明できる
1-24つの尺度について説明できる
1-3度数分布表が作成できる
統計とは
教科書による(医療における)統計学の定義
『個体差のある生物集団を対象とし,調査・実験条件を十分には管理することが出来ないような研究のための方法論』私の考える統計学
『気づかせてくれるもの。うすうす気づいていることを確認するもの』私の考える医療統計学(2015)
『ある事象のなかで一般化出来るもの(法則性)を見いだすことは、その個別の事例にとどまらず広く利用できる知見をもたらす。そのためには複数の事例を集めて検討する統計処理が必要になる。それゆえ、統計処理は個別の事情を発生頻度により排除する主義に基づく。
私達の周りで起こる様々な事象は自然現象によるものだけではなく人間活動などの人工的な要因の影響を受けるものも多く、そのため法則性を見いだすにはそれぞれの領域の目的に応じた統計処理が必要となる。
医療統計学は、単に生物としてだけではなく活動状況も多様な集団である人に対して、提供する医療が及ぼす影響やその要因に関する法則性を見いだす方法を探求する学問分野である。』
(複雑なため確定的な事象はなく確率的に取り扱う必要がある)
統計の分類
記述統計と推測統計に分類される記述統計とは
・収集したデータを要約してその集団の状況を表す・そこにあるデータは全体(母集団)
・度数(分布)・代表値・散布度など
推測統計とは
事象の起こる確率を仮定した上で全体(過去・現在だけではなく未来も含む)を推測する。推定と検定に分類される。推定とは
・収集したデータを基にしてその集団の状況を表す・そこにあるデータは一部(標本)
・点推定・区間推定
検定とは
・収集したデータを基にしてその集団の状況を仮定に従ってyes/Noで判断する・そこにあるデータは一部(標本)
・t検定・カイ二乗検定など
母集団とは
対象としている集団の全体を指し示すときに「母」を最初に付ける。無限母集団と有限母集団からなる。
対象が有限か無限に増殖するかの違い
標本とは
母集団の一部。昆虫標本を思い浮かべると、偏りに注意する必要があることは自明。
参考
標本調査はサンプル抽出が命(The Huffington Post Japan)http://www.huffingtonpost.jp/nissei-kisokenkyujyo/sample-survey_b_5878832.html
変量(データ)の分類
変量は様々なものがあるがそれらの性質をとりまとめ分類することが出来る。それぞれを尺度と呼び、4つに分類するのが一般的である
1名義尺度
2順序尺度
3間隔尺度
4比例尺度
1,2を質的変量(定性的)
3,4を量的変量(定量的)
性質としては上位互換性があり
4>3>2>1
度数分布表
それぞれのデータ(変量)の数(出現頻度)をまとめたもの変量が名義尺度の時は多い順(お作法として。但しその他を出すなら一番最後)
順序尺度以降であれば順(名義尺度でも比較のためにお作法を破ることはある)
度数 ・・・出現頻度
累積度数・・・上位の変量の度数もあわせた度数
相対度数・・・総出現頻度を1(100%)としたときのそのぞれの度数のしめる割合
累積相対度数・・・累積度数の相対版
度数分布図
度数分布表をグラフ化したもの縦棒グラフだが量的変量に限っては「ヒストグラム」その棒の部分の面積が度数を示している
スタージェスの公式
量的変量の度数分布表・図作成の時に階級幅設定の参考になる公式K(階級数)=1+log2(サンプル数)
今回の配付資料のサンプル数は50なので
1+5.64=6.64
7ぐらいが適当
上記を参考にしながら階級幅を決めるとよい(かも程度で)
参考:ヒストグラムは怖い-スタージェスの公式(高校数学の問題を作る -工夫・コツとデータ- )
http://www10.plala.or.jp/mondai/columun/hist.pdf
(経験則に基づいたものだとばかり思っていたのでビックリ)
到達度確認
1)記述統計と推測統計についてまとめよ2)4つの尺度についてそれぞれの変量の例をあげ説明せよ
3)配布した血液検査データのRBCについて度数分布表・度数分布図を作成せよ
授業後補足
|
教科書該当ページ 尺度,変量,母集団,標本 1章P4- 度数分布表,ヒストグラム 4章P36- 到達度確認で気になったポイント 記述統計は対象そのものを示すだけ、示しているものが全てだが、全体とは限らない 自己紹介の話。私の履歴書の一部を紹介されただけ。それが抽出された標本で偏りが生じてしまう 20-30と20代 30-40と30代 の関係は比例尺度(量的変量)なのか順序尺度(質的変量)なのかのちがい 統計の世界と私達の直感のズレ 生物に限らずだが、世の中の事象は確率的な事象での世界で理論上100%以上の確率になりそうだなと思っていても計算上はそうならないし実際に確定的な事象では無い 例:コインの表裏の出る確率はともに50%。理論上2回投げたら表裏一回づつのハズ。つまり2回コイントスをすれば表が出る確率は50%+50%で100%だと考えたいですよね。 実際には2回コイントスをすると0回,1回,2回表の出てくる可能性があるわけで、それぞれ25%,50%,25%。1回以上だから75%となりますが、その通りいくかどうかは? 数式で表すと1-(1/2)^2=0.75 この時点から確率論って期待(願望)を裏切ります。 野球で打率2割5分のバッター。4回打席に入れば1本ヒット打つだろう。今日は3打席ノーヒットだから次は必ず打つ!!と応援 1打数でヒットを一本打つ確率 1-(0.75)^1=0.25 4打数でヒットを一本以上打つ確率 1-(0.75)^4=0.68 100%からかけ離れております。期待しすぎなのでしょう。 イチローは34打席連続無安打をしましたが (2015の打率.229ですが)34打席になると 34打数でヒットを一本以上打つ確率 1-(0.75)^34=0.9999 それでも100%にはならない世界です。 ポイントは打つ確率では無く打たない(無)の事象の確率を使って計算するところですね。 「無」の反対は「有」です |
第2回 記述統計(Ⅱ)-代表値について
到達目標2-1代表値にどのようなものがあるか説明・計算することが出来る
2-2度数分布表から平均値などの算出が出来る
代表値と散布度があると(構成数nもですが)その集団がどんなものか想像出来る(マラソン実況)
代表値
average(その集団を数値一つで表す。excelはaverage関数で算術平均を出すが、まぁ代表値の代表ということだからと解釈しています)算術平均
mean(算術平均以外にも相乗平均(積して累乗根をとる)などもあります)1/n・Σxii
正社員男性の平均給与「527万円」 引き上げているのは誰なのか?(BLOGOS-キャリコネニュース2014年10月04日)
http://blogos.com/article/95831/
中央値
median(別名第2四分位数)量的変量を順序尺度で処理した代表値
順番に並べたとき真ん中の順位にきた個体の値
個体数が偶数の時は真ん中2つの数値の平均値
スキージャンプの飛型点は中央値的なノリで算術平均している
スキージャンプを知ろう!!ルール解説(ジャンプ雪印メグミルク)
https://www.meg-snow.com/jump/rule/rule.html
最頻値
mode(流行,はやり)違う意味で数の理論(多数決)の世界
量的変量を名義尺度で処理した代表値
名義尺度でわかることは一緒か違うか
階級毎に度数をカウント
一番多いところの階級値
一位が同点の時は併記(平均をとると えっオレ優勝!?状態になる)
度数分布表から算術平均を計算
Σ(階級値×度数)/構成数
到達度確認
1)外れ値の影響を受けやすい代表値を示し理由を説明せよ2)前回配布した血液検査データのRBCについて代表値をそれぞれ求め、前回作成の度数分布表より平均値を概算せよ
授業後補足
|
教科書該当ページ 4章P40- 到達度確認で気になったポイント 外れ値の話。統計の個別の事情を排除する主義から考えると平均値だけはどの数字も見捨てていない。 階級値は(上限-下限)/2+下限 なんですけど、(上限-下限+2下限)/2となり (上限+下限)/2 表計算ソフトが無い時代の人たちはこのようにして本来記述統計なのに推計していたわけで(度数分布表より平均値) |
第3回 記述統計(Ⅲ)-散布度について
到達目標3-1散布度にどのようなものがあるか説明・計算することが出来る
散布度・・・dispersion
最大値と最小値を使う
最大値と最小値がわかればその集団のバラツキがわかる最大値maximum excel max関数
最小値minimum excel min関数
範囲
RangeR=最大値-最小値
特徴
外れ値もひらう
算出が用意
四分位数を使う
Quartile小さい順(昇順)に並べて集団を4分割
第1四分位数 First Quartile:Q1 = 25th percentile 25%タイル値
第2四分位数 Second Quartile:Q2 = 50th percentile 50%タイル値 = Median 中央値
第3四分位数 Third Quartile:Q3 = 75th percentile 75%タイル値
四分位数の求め方・・・厳密には数種類ある
授業では簡易に求められるヒンジ値を使用
参考記事 ダンゴ包丁理論(MedBBexblog)
http://medbb.exblog.jp/12047409/
四分位範囲
IQR(interquartile range)IQR=Q3-Q1
四分位偏差
QD(Quartile Deviation)QD=IQR/2
範囲は個々の値のバラツキをイメージ
偏差はある値からのズレをイメージ
平均値を使う
mean偏差
Deviationもともとは標準となる数値からのズレ(偏り)を意味するものだが統計の世界では集団の平均値からのズレを示す
偏差の平均をとれば集団内の各々のズレっぷりがわかる → 合計は常に0 故に平均も常に0
分散
varianceV excel関数はVAR
偏差の二乗したものの平均
標準偏差
Standard Deviation記号は標本s 母集団σ
s=√V
(故にVはs^2やσ^2で表現する)
到達度確認
1)前回配布した血液検査データのRBCについて散布度をそれぞれ求めよ授業後補足
|
教科書該当ページ 4章P40- 到達度確認で気になったポイント サンプル数多かったので標準偏差を出すためにみなさん一苦労され力尽きてました テストで出すときはサンプル数を減らしますので、一度自分で完全に出来るようにやっておいてください |
第4回 記述統計(Ⅳ)-相関係数・回帰直線
到達目標4-1相関係数を説明・計算することが出来る
4-2回帰直線がどのようなものか説明することが出来る
相関
correlative相関関係がある・・・関連がある
相関関係が無い・・・関連がない
他方の影響を受けるか受けないか
因果
cause and effect原因と結果
因果関係がある・・・影響がある
因果関係が無い・・・影響がない
普通は関連がある(相関がある)=影響を及ぼす関係(因果関係がある)と考える(考えたくなる)
例
たばこを吸う-肺がん・・・・相関関係○
タバコを吸う人にコーヒーを飲む人が多いのは・・・(yahoo知恵袋)
http://detail.chiebukuro.yahoo.co.jp/qa/question_detail/q1293675642
この関係を使うと
コーヒーを飲む-肺がん・・・相関関係○
コーヒー愛飲者に肺がんが多い理由は?生活習慣との関連を検証
アメリカで約50万人を対象にした調査から
from International journal of epidemiology
http://medley.life/news/item/5589521b660815fe00d5ec8e
コーヒーと肺がんの相関関係に割り込んでいる(どちらとも相関関係がある)状態=交絡
割り込んでいるそれ=交絡因子・・・たばこ
コーヒーと肺がんに因果関係が無いとしたならその関係は疑似相関
下手な例:電車に乗るとき皆がそれぞれ駅に向かって仲良く歩いてるように見えるが、互いに関係は無い。
この授業(統計学)は医療系対象で「提供する医療が及ぼす影響やその要因に関する法則性を見いだす方法を探求する学問分野」(再掲)
知りたいのは「影響」であるから目的を見失わないように
相関図
X軸とY軸に一つの対象に与えられるそれぞれの値をプロット(例:身長と体重)とりあえず図にすると関係が直感的にわかる(場合がある)
相関係数
-1から1までの値をとる(教科書P48-4.9式)Xが増加すればYも増加する・・・1
Xが増加すればYは減少する・・・-1
Xが増加しようが減少しようがYは関係ない・・・0
X軸で見たときのバラツキ具合とY軸で見たときのバラツキ具合を元に計算してる
バラツキ=散布度・・・分散・・・偏差の二乗の平均
共分散=ある対象のX軸の偏差とY軸の偏差を乗じたものがベース
| Xの偏差 | Yの偏差 | 乗じた結果 |
|---|---|---|
| + | + | + |
| + | - | - |
| - | + | - |
| - | - | + |
共分散はX軸Y軸のバラツキ具合が混ざっているのでそのままの数字だと解釈しにくい→XとYの標準偏差で除する→相関係数
教科書の数式はここで述べていることと同じなのですがちょっと、いろいろな話を盛り込まないといけないので割愛(P47 4.6式)。
直線では無い場合は変数変換(例えば対数変換)してから計算する。
回帰直線
X軸の値とY軸の値を数式(y=ax+b)で示す直線を引いたときにそれぞれの点からの差(残差)の2乗して足したもの(平方和)が最も小さい時の数式が回帰直線
決定係数
相関係数を二乗したもの数式によって説明できる割合を示す。(寄与率とも)
高ければ高いほど数式で説明出来る
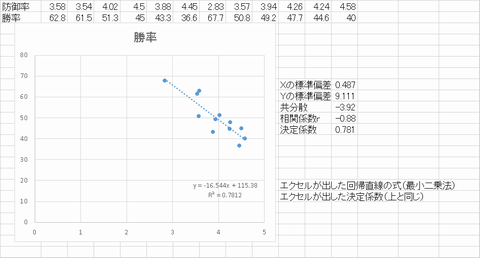
到達度確認
1)P46表4.9のデータを用いて防御率と勝率の間の相関係数を求めよ2)P46表9の勝率yの防御率xに対する回帰直線がy=-15x+100だったとして、優勝するために最低80勝必要とした場合防御率は何点以下である必要があるか
3) 2)で示した式y=-15x+100の決定係数を求めよ
授業後補足
|
教科書該当ページ 4章P40-55 到達度確認で気になったポイント 分散と共分散の話は自分自身を掛ける(自乗)のか、その個体が持つXYのデータを掛けるかの違い 相関図にそれぞれの平均値で区切れば4分割できるわけ 相関係数はその四つの箱の中にどれだけデータが入っているのかの競争 |
第5回 推測統計(Ⅰ)-推定
到達目標5-1標準誤差がどのようなものか理解することが出来る
5-2中心極限定理を説明することが出来る
点推定
母数の推定算術平均・・・母平均の点推定値
分散・・・母分散の推定値
比率・・・母比率の推定値
欠点:どの程度母数に近いのかよくわからない
区間推定
ある確率分布に従うと仮定したときに、その分布に基づき、推定に幅を持たせる-----
確率の話
二項分布
コインを一回投げて表の出る確率0.5=p(事象の起こる確率)表の出る回数x 試行回数n
P(X)=nCx・p^x・(1-p)^(nーx)
表の出る回数3 試行回数10
P(X-3)=10*9*8*7*6*5*4*3*2*1/((7*6*5*4*3*2*1)*(3*2*1))・0.5^3・(1-0.5)^(10-3)
=10*9*8/(3*2*1)・0.125・0.0078125
=0.1171875
教科書P25例題3の場合(サイコロ5回で1の目2回)は
P(X=2)=5*4*3*2*1/(3*2*1*2*1)・(1/6)^2・(5/6)^3
ポアソン分布
二項分布(試行回数nと成功の確率p)→(事象の起こる回数=npを一定にして試行回数を↑確率↓)→ポアソン分布発生確率の低い(pが非常に小さい)事象が従う(とされている)
npの積λさえあれば求められる(事象の起こる回数さえ推定(過去の事象の平均など)できれば)
事象が起こる回数の確率を推定できる
正規分布
二項分布(試行回数nと成功の確率p)→(試行回数を無限大 確率を一定)→正規分布起こる確率(チャンスを掴む確率)が一定であるとしても積み重ねていくことでバラツキ(差)が出てしまう
人など生物の成長に関わるものなどは、正規分布に近いとされている
平均値μと分散σ^2で確率が決まる
常に曲線下の面積=1(100%)。といって裾野は広がるばかりで閉じない
中心極限定理によりかなり強力(通用しない相手にコーシー分布がいる)
中心極限定理
母集団の分布によらず、抽出した標本の平均値は表本数が大きくなるほど近似的に正規分布に従う<参考>可視化で理解する中心極限定理 #rstatsj
http://qiita.com/hoxo_m/items/746d9f62825d410a5982
-----
区間推定の話に戻る
・標準正規確率表の見方・標準誤差(母平均の区間推定の値)と標準偏差(標本のバラツキ)の違い
与えられたデータから、なにかしら推定するための根拠として確率分布を使うという話
詳しくは教科書P60-
到達度確認
1)P47表10のデータは母集団100人の中から16人を抽出したものである。母集団の分散(母分散)が30であると仮定して母集団の平均身長μを95%と99%で推定せよ2)中心極限定理とはどのようなものか、サイコロを思い浮かべながら説明せよ
授業後補足
|
教科書該当ページ 3章P23-P29 5章PP58-635 到達度確認で気になったポイント 中心極限定理の話と標準誤差を説明したグラフ http://aoki2.si.gunma-u.ac.jp/lecture/SampleSurvey/samplesize.html サンプル数が多いほど標本平均のバラツキは小さくなる→1/√n倍で 何故1/√n倍に小さくなるのか・・・誤差の伝搬として考える (感覚として)→誤差(偏差)はサンプル数とともに増加するものの相殺するので単純に増加(≒n倍)せず、相殺する。 全体の誤差は誤差伝搬の法則に従うとして y=f(x1,x2,・・・,xn) ここでは平均の話なので y=1/n*Σxi =1/n(x1+x2+・・・+xn) σy^2=(∂f/∂x1)^2*σx1^2+(∂f/∂x2)^2*σx2^2+・・・+(∂f/∂xn)^2*σxn^2 ここで与えられているのは標準偏差(母じゃない場合は標本からの推定値)となると、σx1^2=σx2^2=σxn^2=σx^2 偏微分をしたら(ここでは詳しく触れないけど) (∂f/∂x1)=(∂f/∂x2)=(∂f/∂xn)=1/n になります。 ∴σy^2=(1/n)^2*σx^2+(1/n)^2*σx^2+・・・+(1/n)^2*σx^2 =n*(1/n)^2*σx^2 =(1/n)*σx^2 ∴標準誤差=σ/√n 私が頭の中を整理するために参考にした資料です。 測定値誤差とデータ解析の基礎事項 : 最小二乗法とランタニド四組効果(川邊岩夫,2013 ) http://hdl.handle.net/2237/18614 誤差伝搬の法則(測量学Ⅰ講義資料 高木方隆) http://www.infra.kochi-tech.ac.jp/takagi/Survey1/3Error.pdf 放射線の計算や測定における統計誤差(第4回関西EGS5ワークショップKEK教材 KEK放射線科学センター) http://rcwww.kek.jp/egsconf/2010-course/comp_rad_phys_2010.pdf |
1)
平均 163.1cm
母標準偏差=sqrt(30)≒5.48
標準誤差=5.48/sqrt(16)=1.37
95%:163.1-1.96*1.37=160.4 , 163.1+1.96*1.37=165.9
[160.4,165.9]
99%:163.1-2.58*1.37=159.6 , 163.1+2.58*1.37=166.6
[159.6,166.6]
意味合いを理解するためにP62図5.4を眺めておくこと
第6回 推測統計(Ⅱ)-t検定
到達目標6-1仮説検定の手順について説明できる
仮説検定
<大前提>やみくもに検定するのではなく、検定する理由・確信があるから確かめる という感じで手順1:仮説をたてる(帰無仮説H0および対立仮説H1)
背理法に基づく証明をしている。
(差がない仮説が証明できないので、その対立である差がある仮説を採択する)
手順2:有意水準を決める
確率的に必然と偶然を切り分けている。一般に5%で分けているが1%の時もある
手順3:検定統計量を計算する
その事象の起こる確率を計算していることになるが、用いる確率分布によって計算式が異なる。
手順4:有意水準と比較し、仮説を棄却採択する
例)帰無仮説H0を棄却し対立仮説H1採択
t分布
正規分布に基づき確率を求めるには母平均と母標準偏差が必要→nが多い場合標本平均と標本標準偏差で近似できるがnが少ない場合は近似できない→t分布(標本の自由度νさえわかっていれば、後は検定統計量を求めれば確率がわかる)
<参考>Points of significanceコラム2:統計における推定と検定 (2)(一人抄読会)
http://syodokukai.exblog.jp/20853048/
自由度
考え方・・・標本の中で自由に振る舞うことが許されている個体の数
統計値が母数の推定となると、自由に振る舞えない個体が出てくる(つじつま合わせ)
標本分散は偏差二乗和を個体の数で除することで求めるが母分散のほどよい推定である不偏分散はn-1(自由度)で除する
<参考>とりあえずt検定やってみたという統計の話(medbb.net)
http://www.medbb.net/education/ocrstat2015/img/01toriaezu.pdf
到達度確認
これはある病院(従業者数300人)で実施した健康診断一部署(放射線室)の身長の記録である| 性別 | 人数 | 平均値(cm) | 不偏分散 |
|---|---|---|---|
| 女 | 11 | 152.5 | 25 |
| 男 | 13 | 160.3 | 9 |
1)女群、男群それぞれの自由度を求めよ
2)帰無仮説,対立仮説をたてよ
3)標本データに基づく検定統計量(確率変数Tの実現値)を求めよ
4)有意水準より棄却域を求め比較せよ
5)検定の結果を述べよ
授業後補足
|
教科書該当ページ 5章P63-69 6章P71-77 所感もろもろ 有意差検定での注意!! キチンと研究デザインがなされていれば 統計的有意差があれば臨床的有意差もある(ハズ) ただただ、やみくもにあるデータを検定する→注意が必要 統計的有意差≠臨床的有意差 仮説検証型は判定を終えたところがゴールだが、探索的に行うものは判定を終えたところがスタートみたいなもの。 授業では普通のt検定を行ったが、近年はソフトで演算を行い改良型のウェルチのt検定を行う (等分散が云々関係なしに) 無の反対は有。好きの反対は嫌いでは無く無関心という話をしましたが、「無関心の反対は関心がある」で、好きでも嫌いでも「関心アリ」なので、なんでも良いんですよね。 故に対立仮説をたてるときは良く考えないとならない |
1)
女 10
男 12
2)
H0 μ1=μ2
この病院の女性の平均身長と男性の平均身長は等しい
H1 μ1≠μ2
この病院の女性の平均身長と男性の平均身長は異なる
3)
T=4.72
4)
t22(0.05)=2.074
T>t22(0.05)
5)
帰無仮説を棄却し対立仮説を採択する
つまりこの病院における女性と男性の平均身長は異なる
第7回 推測統計(Ⅲ)-カイ二乗検定
到達目標7-1周辺度数から期待度数を算出することができる
7-2カイ二乗の検定統計量を求めることが出来る
本来あるべき姿(期待度数)と実際に測定されたデータ(測定度数)がどれだけかけ離れているか、その出現する確率を見ている
手順3の部分の手順
1-観察して度数を記入(観察度数)2-観察度数より周辺度数を求める(いわゆる合計)
3-周辺度数から期待度数を求める(CTの画像再構成の話を彷彿とさせる)
4-それぞれの観察度数と期待度数の差の二乗を求め、それを期待度数で除する(量的変量の分散の話に似ている・・・偏り)
5-4で求めた値を全部足す(これが検定統計量)