奈良県立医科大学 生物統計学2021
(医学部医学科)
|
CMCではYouTube Liveによる動画配信を行います. 講義/復習動画閲覧のログインID,パスワードは教務システム(ActiveAcademyAdvance)の 授業掲示板をご覧ください. CMC分は復習用の動画を配信後閲覧できるようにします. 授業に関する質問はTeamsのチャットでお願いします. |
講義/復習動画の閲覧はこちらから |
授業メニュー
ハイブリッド形式での授業になります.第01回FTF オリエンテーション(授業概要,記述統計と推測統計,統計データの利活用)
第02回FTF 尺度・度数分布・代表値・散布度
第03回CMC 平均値の推定
第04回CMC 検定の原理
第05回CMC パラメトリック検定
第06回CMC ノンパラメトリック検定
第07回CMC 計数値データの検定
第08回CMC 独立多群間の比較
第09回CMC 相関係数・回帰直線
第10回CMC 多変量解析
第11回CMC 相対危険
第12回CMC ロジスティック回帰モデル
第13回CMC 感度・特異度・ROC曲線
第14回CMC 生存時間分析
第15回FTF まとめ(統計処理を行う上での注意点)
本授業の位置付け
医学教育モデル・コア・カリキュラム(平成28年度改訂版)をベースに構成http://www.mext.go.jp/b_menu/shingi/chousa/koutou/033-2/toushin/1383962.htm
本講義が医学教育モデル・コア・カリキュラムにおいて担う部分・関連のある部分
B社会と医学・医療
B-1 集団に対する医療
B-1-1) 統計の基礎
確率には頻度と信念の度合いの二つがあり、それを用いた統計・推計学の有用性と限界を理解し、確率変数とその分布、統計的推測(推定と検定)の原理と方法を理解する。
B-1-2) 統計手法の適用
医学、生物学でよく遭遇する標本に統計手法を適用するときに生じる問題点、統計パッケージの利用を含めた具体的な扱い方を修得する。
B-1-4) 疫学と予防医学
保健統計の意義と現状、疫学とその応用、疾病の予防について学ぶ。
以下の部分は統計データで話が出来たらと思っています.
B-1-7) 地域医療・地域保健
地域医療・地域保健の在り方と現状及び課題を理解し、地域医療に貢献するための能力を獲得する。
本授業の目的
生物統計学は、保健医療分野における課題を統計的手法により明らかにし解決に資する学問である。ここでは、統計学の基礎から本分野においてどのような統計的手法が用いられてきたのか理解し、データの収集・解析・結果の解釈に必要とされる基礎知識を修得する。本授業の到達目標
0)統計手法など必要に応じて「勉強すれば出来るようになる能力」を獲得する1)データの性質に関して説明できる
2)基本的な統計指標を算出できる
3)統計的推定を理解し実施できる
4)統計的検定を理解し実施できる
5)データを取り扱う上での注意点を説明できる
教科書
新版統計学の基礎 第2版http://www.nikkyoken.com/catalog/catalog_education/642
参考図書
授業中に紹介します参考資料
必要に応じて適宜配布しますがなるべく配布せずに済むように出来たらと思っています授業の進め方
電卓使いますのでよろしくお願いします(授業中はスマホでかまいません。試験はどうしようか考え中)
単位認定
授業中に示す課題の提出(30%) 定期試験(70%)課題の提出は教務システムからのみ受け付けます.
授業開講日の翌々日の22時までとします.
提出は手書きで経緯もわかるように記してください.ノートを写真で撮りPDF化して提出してください.(エクセル,ワードなどは禁止します)
課題の提出を以て出席とします.ただし提出の際内容が不十分な場合は減点対象とします.
但し後で指定する期間内に修正した場合減点しません.
また白紙など課題に取り組んだ形跡が見られない場合は欠席および減点とします.
学籍番号氏名がノートに記されていない場合も欠席及び減点とします.
課題について集計したものや学習指導上皆で共有したほうが良いものについてはフィードバックしていこうと考えています.
あと,設問に関係ないけどほのぼのした内容も時々出せたらと思っています.
第01回FTF オリエンテーション(授業概要,記述統計と推測統計,統計データの利活用)
到達目標1-1 記述統計と推測統計について説明できる
1-2 統計データを利用するにあたってどのような問題があるか考えることができる
統計の世界の枠組み
記述統計と推測統計に分類される記述統計とは
・収集したデータを要約してその集団の状況を表す・そこにあるデータは全体(母集団)
・度数(分布)・代表値・散布度・相関係数など
推測統計とは
事象の起こる確率を仮定した上で全体(過去・現在だけではなく未来も含む)を推測する。推定と検定に分類される。推定とは
・収集したデータを基にしてその集団の状況を表す・そこにあるデータは一部(標本)
・点推定・区間推定・モデリング
検定とは
・収集したデータを基にしてその集団の状況を仮定に従ってyes/Noで判断する・そこにあるデータは一部(標本)
・t検定・カイ二乗検定など
母集団とは
対象としている集団の全体を指し示すときに「母」を最初に付ける。無限母集団と有限母集団からなる。
対象が有限か無限に増殖するかの違い
標本とは
母集団の一部。昆虫標本を思い浮かべると、偏りに注意する必要があることは自明。
参考
標本調査はサンプル抽出が命(The Huffington Post Japan)http://www.huffingtonpost.jp/nissei-kisokenkyujyo/sample-survey_b_5878832.html
統計処理について
集団から個々のデータをとりまとめて示すので・・・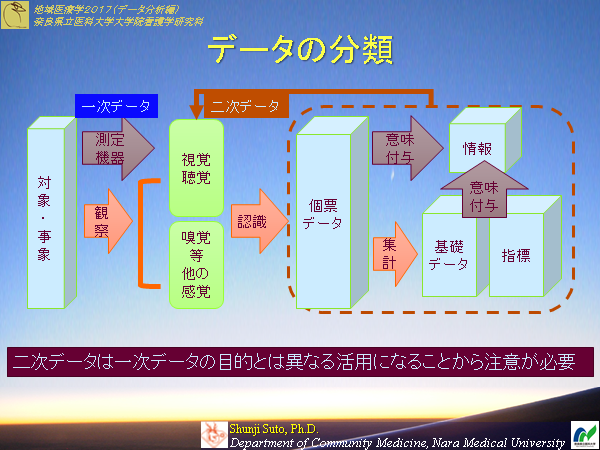
(奈良県立医科大学大学院看護学研究科 地域医療学(分担:データ分析編) より)
データは目的に応じて丸めたり切ったりしてしまう。故に二次利用の場合は注意が必要。
とりあえず収集してデータベース構築をすることが目的ならば、分析は既に二次利用。耐えうるデータを目指さなければ意味が無い
・一次データは情報源からダイレクトに取得するので粒度を目的にあわせてコントロールしている
・二次データは本来の目的と異なるデータ活用となるので、その目的に対してデータの粒度があわない事がある(細かい場合は粗くできるが粗いものは推定するしかない)
医療情報学の分野は二次利用がテーマ
統計データの利活用
一次利用(目的に沿ったもの)であれば,利活用できて当然しかしながら,目的が異なるといろいろ制限が出てくる.
医療圏の話
奈良県保健医療計画(奈良県)http://www.pref.nara.jp/2740.htm
お近くの保健所(奈良県)
http://www.pref.nara.jp/3375.htm
県民アンケート調査(奈良県)
http://www.pref.nara.jp/15126.htm
それぞれの地域分類の違いを示すと
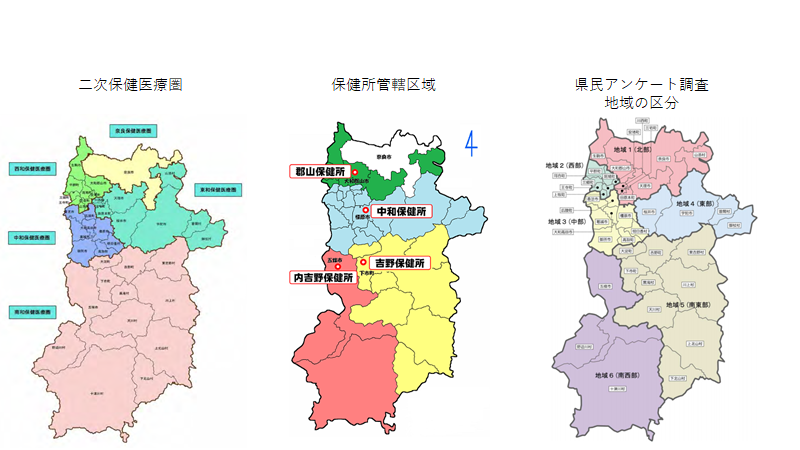
地域別で集計したデータはそれぞれの領域でそのまま使えない
→大元のデータ(個票データ)に立ち返らないといけない
特別講義 オープンデータで読み解く地域包括ケア -不足の観点からみる医療2.21-
https://medbb.net/education/joho20170721
奈良県の医療を取り巻く状況について
https://medbb.net/education/naracommed20190313
上記のような公開された統計データの利用だと,二次利用するに色々限界がある.
新型コロナウイルス特設サイト(Agoop) https://www.agoop.co.jp/coronavirus/
公開されている統計データは入手可能.
個票データの入手には手続きが必要であったり販売していたり,無料で自由に使えるケースは稀
東京都年齢階級別新型コロナウイルスの新規陽性患者数(7日移動平均 人口10万対)3月24日~10月24日. pic.twitter.com/oYriGiJReK
— めどぶぶ (@medbb) October 25, 2020
01授業課題
1)皆さんが卒業するころにはCOVID-19は生活にどのような影響を与えているか【選択肢】
A:収束して以前と同じ生活様式,B:収束するが新しい生活様式,C:完全に収束せず時期により行動制限などがある,D:その他( )
集計して結果はこのページでお見せします.
<参考> 新型コロナ(COVID-19)収束シナリオ見えてきたニューノーマル(新常態)への道筋(MRI三菱総合研究所)
https://www.mri.co.jp/knowledge/column/20210322.html
補足
地域について

地面(地域の区画)を確認してからそこにいる人をみる感じと,そこにいる人を確認してから地面(地域)を見る感じの違い
(北海道大学 病院経営アドミニストレーター育成拠点 産学官連携マネジメント論2018(分担:地域医療と産学官連携) より)
課題について
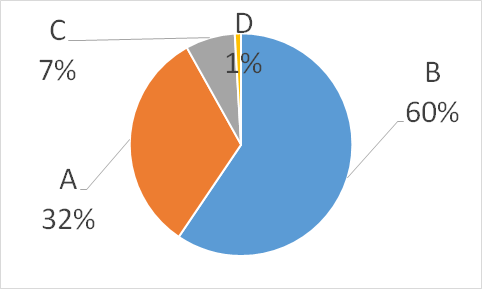
B:収束するが新しい生活様式
消毒うがい集団会食の回避,変異種/新型コロナウイルス以外が流行/ワクチン接種が進むことでインフルエンザと同程度/非常に密なライブなどの状況は許可されない/出入国の制限解除によって罹患する人が出てくる/マスク着用は無くなるがオンライン授業は残る/図書館なども電子化され来校機会が減る /ワクチン対策進む.テレワークなど定着 /マスク着用は定着.完全に終息したという意識はなく感染対策を行っている人が多い /マスク着用が習慣化 /歴史上収束しなかった感染症はないので /換気消毒マスク着用は続く /マスク着用が当たり前になる /アクリル板フェイスシールドマスクが普及し無くならない /既に常識が大幅に変化しているので /基本は依然と同じだがマスクの着用など多少の変化があると思う /在宅勤務や映像授業が引き続き /マスクの着用や大人数での会食は避けるなどのマナーが残る /今でも日本中が新しい様式になれつつあるのでこの先は世界全体が慣れると思う /入学式などの文化は残るがマスクやワークは新しい生活様式 /マスクや手指消毒をやめてもいい日が来るとは思えない /ワクチンが広まることや治療法が確立してほしい /リモートが増える /もともと時が経つにつれて生活様式は変わる.マスク常時着用はその時の世論次第 /手洗いうがいアルコール消毒に気をつける生活 /希望込みで.ワクチンも行き渡っているはず /ワクチンを以てしても完全に0になるとは考えにくく新しい生活様のお願いを続けるだろう /ネット環境の再整備が進みオンライン授業など /マスクやアクリル板A:収束して以前と同じ生活様式
6年後にはワクチンや治療薬が開発されて,元通りになってほしい願いを込めて /期待を込めて /どんな流行病でも収束してきた /これまでの感染症でも元の生活に戻っていくことが多いため /ワクチン接種により戻る /冬になるとインフルエンザワクチンところまワクチンを接種するようになっている /インフルエンザのように予防可能.マスクを外した生活 /ワクチンを接種すればインフルエンザと同じような存在に /数年後には以前のように /全国民がワクチン打ち終えているC:完全に収束せず時期により行動制限などがある
緊急宣言とか時短要請とか /新たな脅威が発生するかもしれない /変異種が流行 /1年前に収束といわれてたのに実際こんな状況だから収束する未来が見えないD:その他( )
収束しないが徐々に以前のような生活スタイルになるのでは(制限が事実上解除となって)第02回FTF 尺度・度数分布・代表値・散布度
到達目標2-1 4つの尺度について説明できる
2-2 度数分布表を作成できる
2-3代表値の算出及び特性について説明できる
2-4散布度の算出及び特性について説明できる

変量(データ)の分類
変量は様々なものがあるがそれらの性質をとりまとめ分類することが出来る。それぞれを尺度と呼び、4つに分類するのが一般的である
1分類尺度(名義尺度)
2順序尺度
3間隔尺度
4比尺度(比例)
1,2を質的変量(定性的)
3,4を量的変量(定量的)
性質としては上位互換性があり
4>3>2>1
教科書は間隔尺度及び比尺度に関して統計処理上区別する意味は無いとなっているが、注意は必要
ポイントは数学的には正しかったとしても意味的に正しいかどうか
度数分布表
それぞれのデータ(変量)の数(出現頻度)をまとめたもの変量が名義尺度の時は多い順(お作法として。但しその他を出すなら一番最後)
順序尺度以降であれば順(名義尺度でも比較のためにお作法を破ることはある)
度数 ・・・出現頻度
相対度数・・・総出現頻度を1(100%)としたときに、それぞれの度数がしめる割合
累積度数・・・上位の変量の度数もあわせた度数
累積相対度数・・・累積度数の相対版
| 品名 | 度数 | 相対度数 | 累積度数 | 累積相対度数 |
|---|---|---|---|---|
| いちご | 15 | |||
| みかん | 8 | |||
| ぶどう | 7 | |||
| 計 | 30 | 1.00 | ----- | ----- |
度数分布図
度数分布を縦棒グラフで示したもの量的変量の場合「ヒストグラム」→縦棒の間隔は無し(量だから)
棒グラフの面積がその度数の量を示す。→ある部分だけ階級幅を倍にした場合度数は半分で描く
例:
(第1回 オリエンテーション 奈良県立医科大学 生物統計学2017(医学部医学科) より)
代表値
average(その集団でとりまとめたデータを数値一つで表す。excelはaverage関数で算術平均を出すが、代表値の代表ということだからと解釈しています)算術平均
mean(算術平均以外にも相乗平均(積して累乗根をとる)などもあります)1/n・Σxi
パレートの法則(80-20の法則)
代表値なのに実在しない場合がある → 集団の指標(重心)であって、事象を代表する値そのものを示しているとは限らない
収入の話
民間給与実態統計2015(国税庁)http://www.e-stat.go.jp/SG1/estat/GL08020103.do?_toGL08020103_&listID=000001159883&requestSender=dsearch
第9表 業種別及び給与階級別の給与所得者数・給与額 より ローレンツ曲線
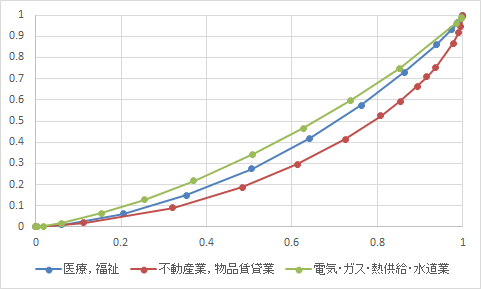
ジニ係数は医療,福祉0.358 不動産業,物品賃貸業0.439 電気・ガス・熱供給・水道業0.230
ちなみに奈良県の医師偏在の話で曲線を描くと(市町村単位)
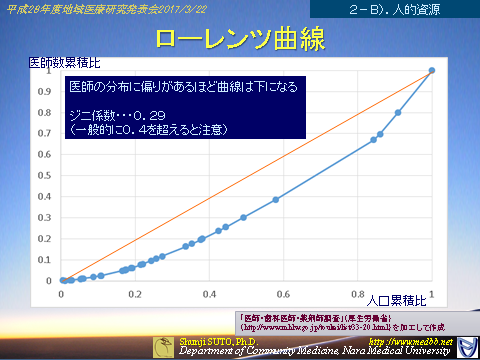
(データ分析から考える地域医療の課題 より)
もっとも地域別医師数偏在の話が解消されればすべてが解決されるわけでもないですし、範囲を狭めていくほど偏在は生じるわけですから・・・
リソースの地理的な偏りをゼロにすることそのものは目的ではなく解決に近づく手段であって、提供になるべく偏りがでないような配分ができる仕組みとのパッケージと考えております
加重平均
重みづけをした平均1/n・Σmixi
応用 度数分布表を基にした平均値の計算法
Σ(階級値×度数)/観測数
中央値
median(別名第2四分位数)量的変量を順序尺度で処理した代表値
順番に並べたとき真ん中の順位にきた個体の値
個体数が偶数の時は真ん中2つの数値の平均値
最頻値
mode(流行,はやり)違う意味で数の理論(多数決)の世界
量的変量を名義尺度で処理した代表値
名義尺度でわかることは一緒か違うか
階級毎に度数をカウント
一番多いところの階級値
一位が同点の時は併記
散布度
dispersion最大値と最小値を使う
最大値と最小値がわかればその集団のバラツキがわかる最大値maximum excel max関数
最小値minimum excel min関数
範囲
RangeR=最大値-最小値
特徴
外れ値もひらう
算出が用意
四分位数を使う
Quartile小さい順(昇順)に並べて集団を4分割
四分位範囲
IQR(interquartile range)IQR=Q3-Q1
四分位偏差
QD(Quartile Deviation)QD=IQR/2
範囲は集団を外から見たバラツキをイメージ
偏差は集団の内部のある値からのバラツキをイメージ
平均値を使う
mean偏差
Deviationもともとは標準となる数値からのズレ(偏り)を意味するものだが統計の世界では集団の平均値からのズレを示す
偏差の平均をとれば集団内の各々のズレっぷりがわかる → 合計は常に0 故に平均も常に0
分散
varianceV excel関数はVAR
偏差を二乗したものの平均
標準偏差
Standard Deviation記号は標本標準偏差s 母標準偏差σ
s=√V
(故にVはs^2やσ^2で表現する)
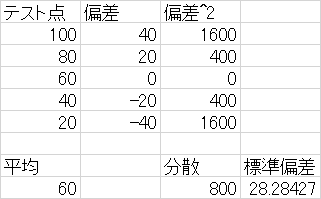
02授業課題
以下の個票データから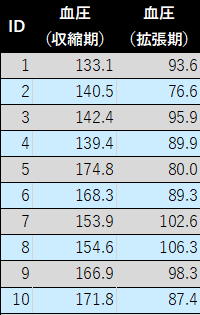
1)収縮期血圧の度数分布表を作ってください(区間は10mmHg刻み)
| 階級 | 階級値 | 度数 | 相対度数 | 累積度数 | 累積相対度数 |
|---|---|---|---|---|---|
| 130~140 | 135 | ||||
| 140~150 | 145 | ||||
| 150~160 | 155 | ||||
| 160~170 | 165 | ||||
| 170~180 | 175 | ||||
| 計 | ----- | ----- |
3)1で作成した度数分布表より収縮期血圧の平均を求めてください
4)収縮期血圧の範囲,四分位範囲を求めてください
5)収縮期血圧の標準偏差を求めてください
補足
四分位数の話
四分位数は出し方が何種類かありますが,本授業ではtukeyの上ヒンジ 下ヒンジで求めます.(高校ではそれで習っているかと)小さい順(昇順)に並べて集団を4分割
注意:順序の話とその順位のラベル(数値)をこんがらがってしまわないように
例:テストの点 16,5,12,16,13,15,15,18,20,10,20
昇順に並べて順位(カッコ書き)をつける 5(1),10(2),12(3),13(4),15(5),15(6),16(7),16(8),18(9),20(10),20(11)
n数(11)を4で割る
第1四分位数・・・1/4の順位・・・11/4×1=2.75個に分割する場所に相当する数値
第2四分位数・・・2/4の順位・・・11/4×2=5.5個に分割する場所に相当する数値
第3四分位数・・・3/4の順位・・・11/4×3=8.25個に分割する場所に相当する数値
2.75個に分割した場所の出し方
+1/4番目の数値=3番目=12
5.5個に分割した場所の出し方
+2/4番目の数値=6番目=15
8.25個に分割した場所の出し方
+3/4番目の数値=9番目=18
ダンゴ包丁理論(tukeyのヒンジ)
https://medbb.hatenablog.com/entry/2020/12/12/091240
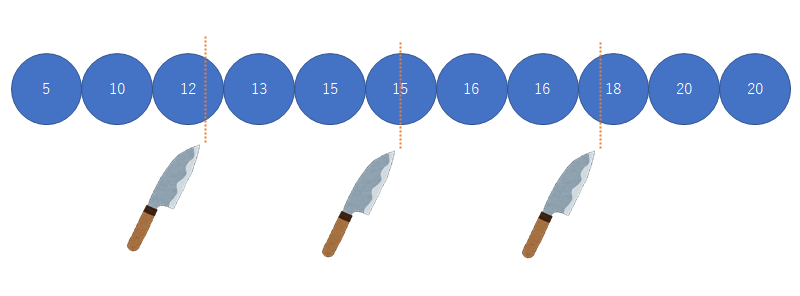
団子を4等分した時にどのダンゴに包丁を入れたか.
課題で気になった部分
提出方法
氏名学籍番号なし(欠席になっています.teamsで連絡ください) ,手書きじゃない ,HEIC形式やめて ,解答選んで ,ファイル破損(出席空欄になっています.teamsで第2回の分送ってください)第2回の内容
四分位範囲計算間違い・・上ヒンジ下ヒンジで,関数は使わない ,標準偏差の計算間違いも多い
第03回CMC 平均値の推定
到達目標3-1標準偏差と標準誤差の違いを説明できる
3-2母分散が未知の場合でも母平均を区間推定できる
教科書P32-40,52-53,70-73,270-271
推定
母集団から抽出した標本を基に母集団の分布を示す値(母数)を推測する点推定と区間推定がある
点推定
一つの値で推定母平均の推定値は標本平均
母分散の推定値は不偏分散
教科書P22-23参照
不偏分散は何故nではなく(n-1)で除するのか
求める対象(標本)が母集団全体だったとすると母分散は(1/n)Σ(xi-xbar)2
しかしながら対象が母集団の一部であれば,母平均(μ)=標本平均(xbar)とは限らないので,
μとxbarの差を考慮して母分散を求める(推定する)必要がある
(1/n)Σ((xi-μ)-(xbar-μ))2
=(1/n)Σ(xi-μ)2-(2/n)Σ(xixbar-xiμ-μxbar+μ2)+(1/n)Σ(xbar-μ)2
=(1/n)Σ(xi-μ)2-2(xbar2-2μxbar+μ2)+(xbar-μ)2
=(1/n)Σ(xi-μ)2-2(xbar-μ)2+(xbar-μ)2
=(1/n)Σ(xi-μ)2-(xbar-μ)2
-----
ここで それぞれ
(1/n)Σ(xi-μ)2=σ2
(xbar-μ)2=σ2/n
(注:詳しくは 「 標準誤差SEはなぜ標準偏差σを√nで除するのか」参照)
とおくと
-----
=σ2-σ2/n
=((n-1)/n)σ2
故に母分散の程よい推定値である不偏分散は
U=n/(n-1)・(1/n)Σ(xi-xbar)2
=(1/n-1)Σ(xi-xbar)2
となる.
区間推定
母数がある確率で入る幅を持った推定値本日の目標はP70の話を理解すること。母平均は一定なのに標本平均は標本毎に異なるので幅を持たせる
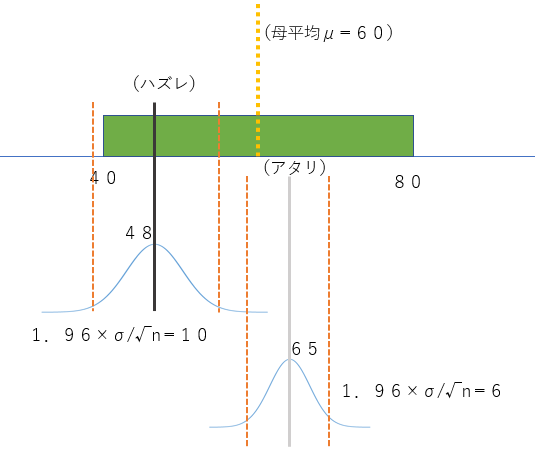
標本平均に幅を持たせることで、その枠内に母平均が入る。→平均値のバラつき具合が標準誤差 SE=σ/√n
標準偏差と標準誤差
(教科書P52)・標準偏差は標本の分布のバラツキ具合を示したもの
・標準誤差は母集団から抽出した標本の平均値のバラツキ具合
SE=σ/√n
標準誤差SEはなぜ標準偏差σを√nで除するのか
標準誤差は母平均に対する標本平均のバラつき指標(標準偏差)の話対象が母集団全体ならば0だが,母平均(μ)と標本平均(xbar)には差が生じる
ある標本における平均値と母平均の偏差平方は
(xbar-μ)2
=((1/n)Σxi-μ)2
=((1/n)Σxi-(1/n)Σμ)2
=((1/n)Σ(xi-μ))2
=(1/n)(1/n)Σ(xi-μ)2
-----
ここで
(1/n)Σ(xi-μ)2
をσ2とおくと
-----
=σ2/n
故に標準誤差は
SE=σ/√n
正規分布
左右対称の釣鐘状分布(教科書P32-40)平均値に近いほど出現率が高く遠ざかるに従って低くなる(ことが多い)
同じ事柄を同じ条件で繰り返すと正規分布になるという話→中心極限定理
「異質な集団の計測値が組み合わさった分布は正規分布とならない」(教科書P33)
正規分布っぽい形状の判断→P28 歪度 尖度を参照
中心極限定理
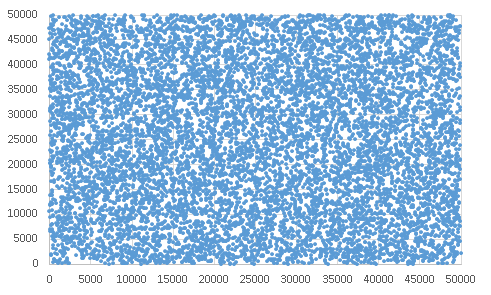
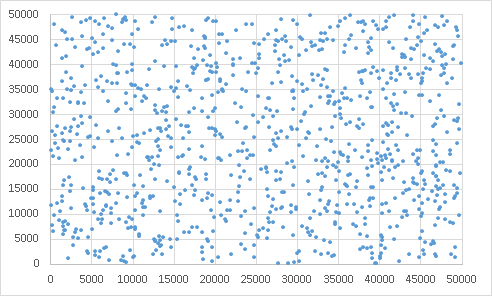
標本の大きさが十分であれば標本平均の分布は正規分布→正しく測定されているのであれば偶然誤差の発生は正規分布に従う
→測定回数を増やせば増やすほど
真度と精度の話(誤差)に置換えると

正規分布の話は精度の話。右に行くほど(精度が悪くなるほど)広がる
ただし均等にバラつくはずであっても試行回数が少ないとばらついて見えることもある
0から49999までの乱数でXY座標を発生させプロット1万回分
0から49999までの乱数でXY座標を発生させプロット千回分
0から49999までの乱数でXY座標を発生させプロット百回分
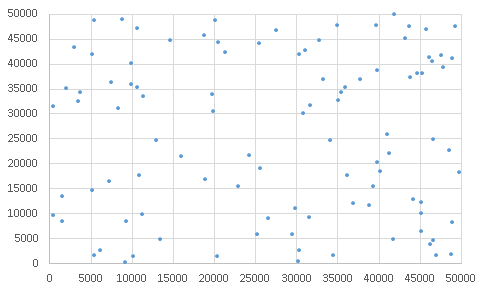
標準正規分布(P37)
平均値が0標準偏差=1(分散も1)になるように値を変換したもの
偏差値は平均値を50、標準偏差=10になるように値を変換したもの
両者の関係
偏差値=50+10×z
ZスコアはP36参照
母標準偏差が既知の場合の区間推定
(教科書P70)正規分布表でなぜ1.96になるのか確認
母標準偏差が未知の場合の区間推定
(教科書P70)正規分布は母平均値と母標準偏差が分からないと使えない→nが多い場合標本平均と標本標準偏差(不偏標準偏差))で近似できるが
nが少ない場合は近似できない→t分布(標本の自由度νさえわかっていれば、後は検定統計量を求めれば確率がわかる)
t分布
P64-66
自由度のみできまる確率分布
自由度・・・標本の中で自由に振る舞うことが許されている個体の数
統計量が母数の推定となると、自由に振る舞えない個体が出てくる(つじつま合わせ)(P73)
標本分散は偏差二乗和を個体の数で除することで求めるが母分散のほどよい推定である不偏分散はn-1(自由度)で除する
正規分布との関係を確認
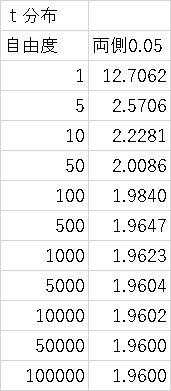
でP70を再度確認
|
この教科書では母標準偏差が既知か未知かによってのみ分けていますが,標本サイズが大きければ未知であっても正規分布を使って推定しているものもあります. 例えば30以上で標本サイズは大きいと判断されている場合もあります. |
検査値の基準範囲について
教科書P35健常者を対象に測定したデータの95%(つまり健常者であっても5%は外れる)
平均値の区間推定は標準誤差を用いるが、こちらの場合は標準偏差。分布に関して考慮する必要がある。
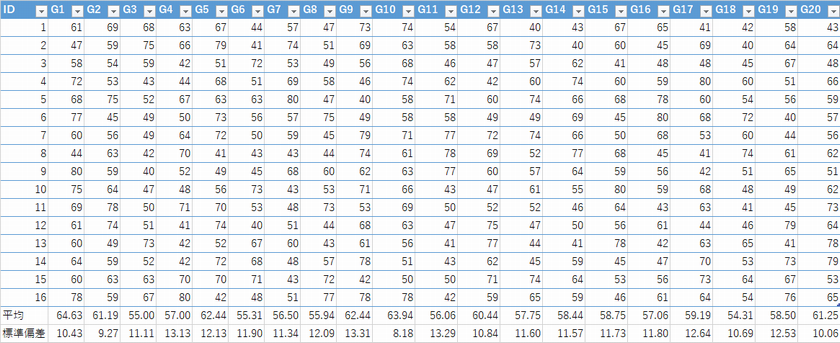
本日の課題
1.P20の生データより母平均の95%信頼区間を求めよ.2.以下の表は母平均が60の母集団からサンプル数16で標本を20通り抽出したものである.
標本標準偏差を用いて母平均の95%信頼区間をt分布で行い,どの程度の確率で母平均が含まれていたのか検証せよ.また正規分布でも同様に検証を行い確認せよ.
補足
課題について
設問2について
再提出の対象外としています.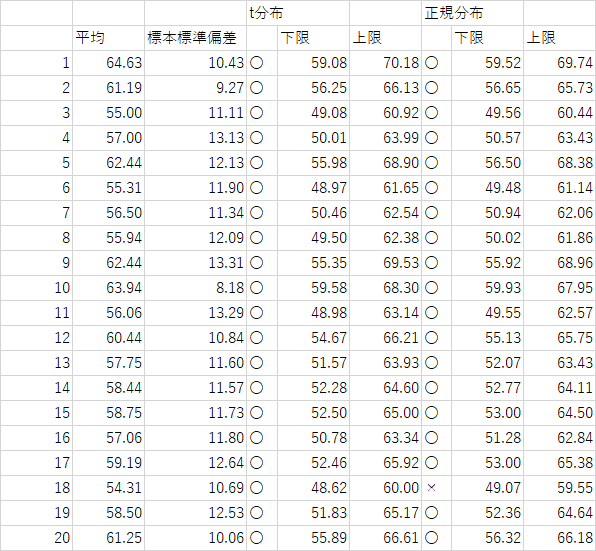
今回はどちらも95%とピタリでしたが,t検定のほうが区間幅が広い分,母平均を含む確率が高くなりそうというのは分かるかと思います
t分布で100% 正規分布で95%という答えが多かったように思います.
ちなみにもう少し標本数を増やした場合でシミュレーションしましたがt検定の方は95%信頼区間では95%の確率だったのですが,正規分布では低くなる結果が得られています.
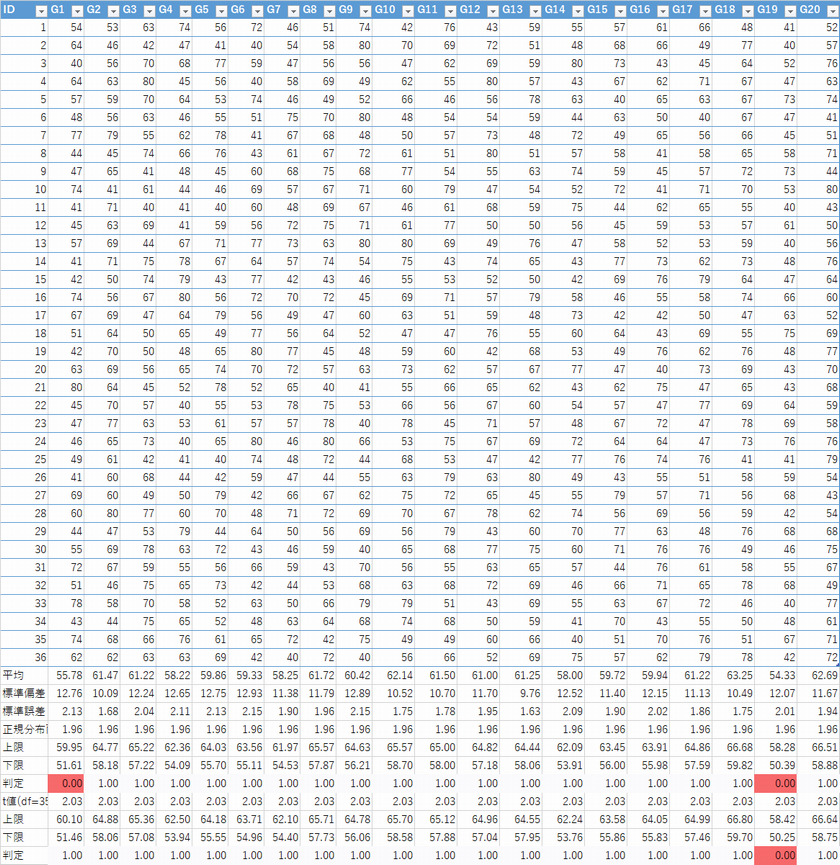 t分布は正規分布では上手く推定できない小標本で用いますが,どこまでが小標本問題?も出てしまいますので,実際にはどのように推定したかを示すことが重要に思います.
t分布は正規分布では上手く推定できない小標本で用いますが,どこまでが小標本問題?も出てしまいますので,実際にはどのように推定したかを示すことが重要に思います.第04回CMC 検定の原理
到達目標5-1確率がどのような意味合いのものか理解する
5-2仮説検定の論理構成を説明できる
教科書P3-7,46-51,207,208,215
確率
ある事象が起こることが期待される度合い(割合)試行 サイコロを振って3の目が出る(y or n)
確率 サイコロを振って3の目が出る(1/6)
繰り返し試行を行うと頻度割合はその事象の確率へ収束していく
生物を対象とした場合試行を繰り返せる?→無理な場合が多い→条件を近づけて繰り返したと見做す
試行の結果は事実で正しい。かといってそれが常に正しい(真)とは限らない
次の試行以降で異なる結果がでる可能性を排除できない→永遠に試行を繰り返さないとならず法則が出せない
(故に異なる現象の起こる確率にたいして閾値を定めて、なかったことにして一般性を主張するスタイル)
事象の起こる確率が著しく低くても、実際に起こらないわけではない。
参考
デジタル絵本 かっぱの雨乞い (札幌平岸高校デザインアートコース)
降るまで雨乞いをするので「雨乞いをすれば雨が降る」となってしまう
参考
単語記事: テレ東伝説(ニコニコ大百科(仮))
http://dic.nicovideo.jp/a/%E3%83%86%E3%83%AC%E6%9D%B1%E4%BC%9D%E8%AA%AC
検定
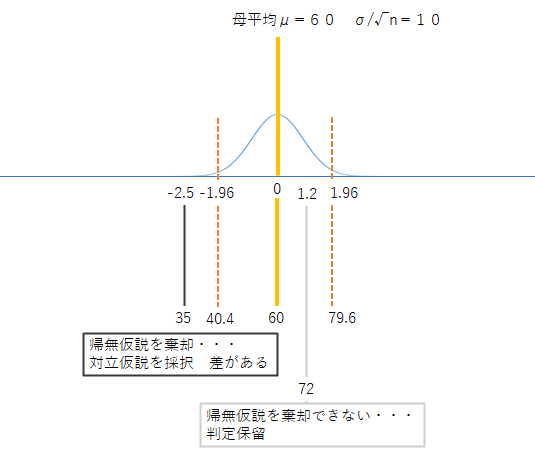
平均値の差の検定・・・平均値の推定との違いについて理解しておいてください.
推定の時は母平均・・・未知(故に標本から推定する)
検定の時は母平均・・・仮説に基づき設定(標本が仮説の範疇に収まるか否か検定する)
背理法(P47)
命題の否定を仮定して話をすすめて、その矛盾を示すことで命題が成り立つとする論法差のあることを証明するにあたって「差が無いことを」を証明できないことを根拠にする
(差(違い)を定義するにも区間推定で明らかなように,確率一定でも値は変化する)
<注>好きの反対は嫌い ではなく無関心という考え方.
仮説検定
教科書P46-<大前提>やみくもに検定するのではなく、検定する理由・確信があるから確かめる という感じで
手順1:仮説をたてる(帰無仮説H0および対立仮説H1)
背理法に基づく証明をしている。(差がない仮説が証明できないので、その対立である差がある仮説を採択する)
手順2:検定統計量を計算する
その事象の起こる確率を計算していることになるが、用いる確率分布によって計算式が異なる。(実データを確率の世界のスケールに変換) 教科書P50では(3)の前半の部分Z= の部分がそれ
手順3:有意水準を決める
確率的に必然と偶然を切り分けている。一般に5%で分けているが1%の時もある手順4:有意水準と比較し、仮説を棄却採択する
例)帰無仮説H0を棄却し対立仮説H1採択両側検定片側検定
P207一緒な有意水準で比較した場合 片側は棄却域が存在しないことと,他方は棄却域が大きくなってしまう → 帰無仮説が棄却されやすくなる状況
有意水準は常に0.05?
P208有意差は有意水準が一緒でもn=が大きくなると少ない差でも優位と判定されてしまう.
αエラー βエラー
教科書P215第一種の過誤
αエラーの起こる確率(誤って有意差があると判定)=有意水準
エラーを気にしなければいつの日か、都合の良い結論が得られるかもしれない → 雨乞い
故にやみくもに検定するのではなく、至るまでのストーリーが大切
第二種の過誤(βエラー)・・・誤って一緒と判定する確率
βエラーの起こる確率(誤って有意差が無いと判定)=検出できない=1-検出力(Power)=β
検出力=1-β
サンプル数↑・・・検出力↑・・・β↓
一般に検出力0.8~0.9で違いを見積もった上でサンプル数を決定する
検出力をが上がるとβエラーの確率は下がるが,統計的有意差と臨床的有意差の話が出てくる.
仮説検定は用法を守り正しく使いましょう
例題7(P53)について
この場合は平均値の検定なので標準偏差ではなく母標準誤差の話これが標本平均から母標準偏差を推定する格好で行うと,サンプル数的にも微妙(→t検定)
(t検定のほうが帰無仮説を棄却しにくくする)
標本の平均値と母平均の差をzスコアに変換
(今回は平均値なので)母平均の差を母標準誤差を1の状況に変換したらz値
本日の課題
2017年国民栄養基礎調査によると成人のヘモグロビンA1c(NGSP)(%)の平均値及び標準偏差はそれぞれ,5.80 0.70だった.糖尿病予防の取り組みを行っている会社の従業員100人を対象に測定し平均を求めたところ5.65だった.
有意に異なるといえるか有意水準5%で両側検定せよ.
(P35の分布も確認のこと)
<参考> ヘモグロビンA1c(NGSP)の平均値及び標準偏差 - 年齢階級別、人数、平均値、標準偏差 - 男性・女性、20歳以上〔インスリン注射又は血糖を下げる薬の使用者含む・含まない〕 (国民健康・栄養調査)
https://www.e-stat.go.jp/dbview?sid=0003224190
補足
仮説検定のフォーマット例
手順1帰無仮説H0:μ=100 対立仮説H1:μ≠100
↓
手順2
z=・・・・・ ↓
手順3
有意水準 両側5%としz検定を行う
↓
手順4
検定統計量との比較,もしくは確率の比較により,今回の標本が棄却域にあるのか否か(受容域なのか)判定する.
|z|=3.96>1.96 (有意水準両側5%ならば片側2.5%なので)
帰無仮説を棄却し対立仮説を採択する
有意差がある
例2)
|z|=1.45<1.96 (有意水準両側5%ならば片側2.5%なので)
帰無仮説は棄却されない
判定を保留する
有意差があるとは言えない
課題についての間違い例
判定が逆,仮説の立て方がひどい,計算式がよくわからない,両側片側混在.桁間違い,計算間違い,正規分布表の見方間違い第05回CMC パラメトリック検定
到達目標5-1パラメトリック検定の頑強性robustnessを説明できる
5-2t検定を行うことができる
教科書
第2章P44 計測尺度と統計処理方式第4章P57-69 関連2群の差の検定
第5章P81-101 独立2群の差の検定
第10章P204 Q1,Q2
パラメトリックとノンパラメトリック
教科書P44
分布の形状(母数)に依存する統計量(平均値 標準偏差・・・量的変量)分布の形状(母数)に依存しない統計量(順位 中央値 パーセント値・・・質的変量)
教科書P4-7,204
パラメトリック検定・・・計測値の分布が正規分布であることを仮定正規確率紙法・・・Q-Qプロット
データをノンパラメトリックとみなして順序に直してそこからパーセンタイルを求めて、値を確率分布(正規分布)に代入して期待値を算出して比較する。
P11複雑な調査データTGを用いて
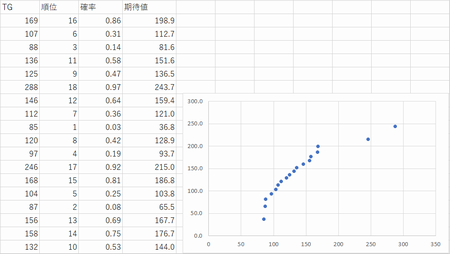
<参考>正規確率プロットの作り方(統計WEB 社会情報サービス統計調査研究室)
https://software.ssri.co.jp/statweb2/tips/tips_8.html
適切な統計処理に必要な考え方
P203-216Q2検定法によって判定が異なる場合
→データが出てから検定法を選択するのは適切ではない
Q5有意差検定が無意味な場合
→統計的有意差と臨床的有意差の話 教科書の効果量に対する必要データ数を可変させたものが以下
各群10データで検定すると10kg程度となるが、そこまで体重が変化しているとなにか違う出来事が起こっている気がする
各群1000データぐらいで検定すると1kg程度で有意な結果となるが、本当に意味あるのか気になる
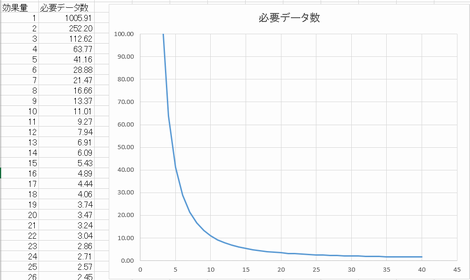
<参考>その治療は臨床的に有益か(PEDro)
https://www.pedro.org.au/japanese/tutorial/is-the-therapy-clinically-useful/
<参考>統計的有意性とP値に関するASA声明
http://biometrics.gr.jp/news/all/ASA.pdf
以下抜粋しました
1. P値はデータと特定の統計モデルが矛盾する程度をしめす指標のひとつ
2. P値は、調べている仮説が正しい確率を測るものではない
3. 科学的な結論は、P値がある値を超えたかどうかにのみ基づくべきではない
4. 適正な推測のためには、すべてを報告する透明性が必要
5. P値は、効果の大きさや結果の重要性を意味しない
6. P値は、それだけでは仮説に関するエビデンスのよい指標とはならない
・データ数大きい場合は区間推定のほうが意味ある。
教科書P6テーブル(適用要件による使い分け)
1標本t検定・・・空白2標本t検定・・・2群の等分散性
空白の意味は、データ元が同じところなので問題にならない
2群の等分散性に関しては、ぞれを前提として検定が成り立っているので(以下に紹介する(スチューデントの)t検定は
無論、等分散ではない場合に用いる検定(ウェルチのt検定)もあるのですが、そちらを最初から使った方が良いという話があります。
ノンパラかパラメトリックの話と同様ですが、どちらでやろうとも有意差が出てるぐらい明確なものが理想ではありますが
2群の差の検定
1標本t検定(関連2群)
教科書P58P60例題8を見ながら
関連する2群(ペア)・・・一つの群を2回測定している
前後の差を見る・・・μ1-μ2=0・・・μ1=μ2
t値(標準化された検定統計量)・・・2群のペアの差の平均を標準誤差で正規化したもの
帰無仮説は前後の差がゼロ
検定統計量と有意水準αのt値を比較する。
2標本t検定(独立2群)
教科書P82~ P84例題12 P87例題13こちらの場合は、教科書的にはF検定(P86)で等分散を確認してからの手順になる。
一標本との違いは分散が2種あること(一標本はペアの差をとるので一つ)
そのため合成する
t値・・・それぞれの群の平均の差を標準誤差で正規化したもの
F分布・・・χ2分布の時にお話しします
2標本t検定と1標本t検定
P60例題8を独立した標本と考えた場合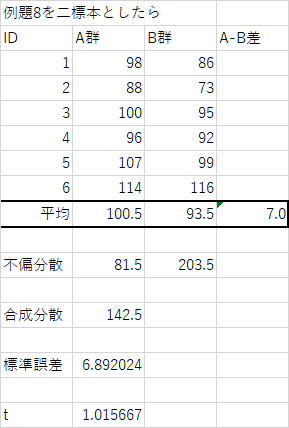
異なる検定結果が出ている・・・
課題
1)以下の前後の脈拍データに有意な差がみられるか検定を行ってください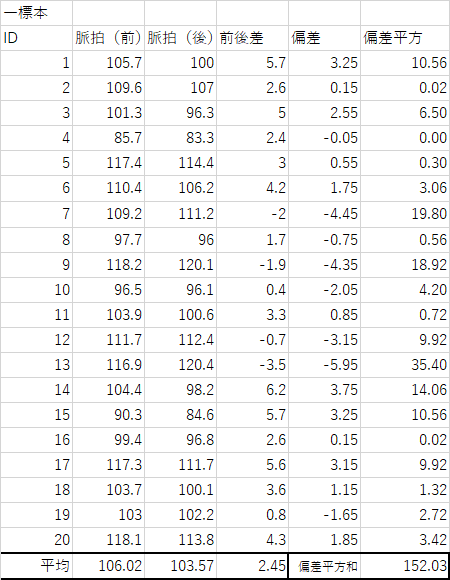
2)先ほどのP60例題8,なぜ異なる検定結果が出ているのか,理由を考えてみてください.
(2は次週解説しますので,どのような答えでも受け入れます.再提出要不要は1)のみ対象です)
補足
課題についてのコメント
1
結論逆,計算間違い,計算式間違い,二標本tをやっている,読めない(再提出対象としていないもの)何と比較してんだ?計算間違えしているけど勘違いだろうな
2
二群の差の平均を考えるのか 個々の差の平均を考えるのか,前値をそろえるのに対して二つの値が独立しているから,合成標準偏差を使うので無理やり感がある,自由度が違うため,合成分散は同一と見做した分散値と一致していない,それぞれの群の差があったとしても母集団中の差と考えられてしまう,免疫システム?バセドウ病のコメント?,体重など他の要素があるから(効き方に差がある),よさそうなこと書いているけど文字読めない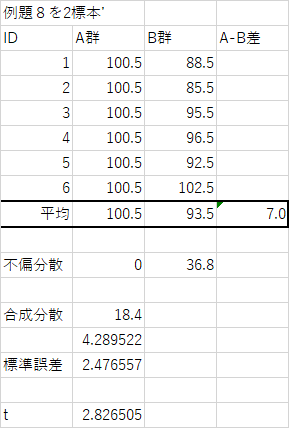
第06回CMC ノンパラメトリック検定
到達目標6-1パラメトリック検定とノンパラメトリック検定の違いを説明できる
6-2ノンパラメトリック検定を行い判定することが出来る
教科書
第4章P74-80 一標本Wilcoxon検定第5章P102-113 Mann-Whitney検定
一標本Wilcoxon検定
ウィルコクソンの符号付順位和検定教科書(P6)・・・分布型,計測尺度,分散の制約なし
教科書(P74)
1:ペアのデータの差dを求める
2:dの絶対値よりそれぞれの差(d)の順位(昇順)を求める
同順位の話・・・教科書P76参照
3:検定統計量Tは+,-別に順位を足したもので小さい方
T0=min(T1,T2)
有意確率については直接計算出来るが(P75)延々と計算していくのは大変
n≦25まではWilcoxon検定表を使ってください(P274)
N数が少ないと(空白の部分)判定保留にしかならない
教科書P78参照のこと
n>25は正規分布に近似と見なしてz値を求める方法で検定
平均値
μT=n(n+1)/4標準誤差
σT=√(n(n+1)(2n+1)/24)検定統計量
Z=(T-μT)/σT連続補正
P137参照P76(例題10)で説明します.
Mann-Whitney検定
二標本になるとややこしくなるのはパラメトリック検定と同じP102-113参照
検定統計量
自群の個々について、それよりも他群で大きい個体数の総和を求めて検定統計量としている
1:ある群(A)の値それぞれがもう一方の群(B)に入ったとしたときに(Aの)その値よりも(Bの群のなかで)値が大きい個数をカウントする。(A群の)全てについて行い和をとる。(順位-1の話)
2:AとBを入れ替えて1:と同様の計算をするか、公式でB群の和を求め小さい方を検定統計量Uとする
同順位の話・・・教科書P103参照
こちらも標本数が多くなると正規分布の話が出てくる
平均値
μU=n1n2/2標準誤差
σU=√n1n2(n1+n2+1)/12)検定統計量
Z=(U-μU)/σUP104(例題17)P110(例題19)で説明します.
課題
6-1)P60例題8についてノンパラメトリック検定を行い、パラメトリック検定の結果と比較せよ。(一標本)6-2)P60例題8を二標本だったとしてノンパラメトリック検定を行い,パラメトリック検定の結果と比較せよ。
補足
質問
これらの検定のどれを採用するべきなのか基準がいまいちわからない
計測値の分布型が未知 且つ データ数が少 → ノンパラメトリック順序尺度はノンパラメトリックが原則だが多段階であればパラメトリック検定を用いる場合もある
課題について
検定表の見方がおかしい,wilcoxon順位ではなく数値そのままで和をとる,検定の結論が逆,U検定量の出し方がおかしい,結論に至るにあたって情報不足,近似式使うほどのサンプル数ではない以下は再提出不要ですが皆さんご確認ください.
U検定量の出し方計算ミスしているが結果に影響していないし告知だけ,仮説の立て方が怪しいが,検定表の部分は単純なミスだろう,それっぽいので理解できていると判断したがわかっているのだろうか
参考
名取 真人,マン・ホイットニーのU検定と不等分散時における代表値の検定法,霊長類研究30(1)173-185,2014https://www.jstage.jst.go.jp/article/psj/30/1/30_30.006/_article/-char/ja/
第07回CMC 計数値データの検定
到達目標7-1二項分布と正規分布の関係を説明できる
7-2カイ二乗分布がどのようなものか説明できる
教科書P125-151
計量値と計数値
計量値・・・量を測定計数値・・・頻度を測定(名義尺度)
量的変量は頻度の測定も出来る.(連続量から変換する必要があるけど)
どのようなデータにも使えるので,色々なところで出てくる
二項分布(高校で習ってますよね)
標本の大きさ=n事象の起こる確率=p
r=出現度数
np=n回試行を繰り返したときに事象の起こる回数(期待度数)
例題22(P128)で述べている発生率は期間有病率(つまり割合)のこと.
|
比と率と割合の違いについて 比・・・異なるものを比較(無単位になる場合もあるが) 率・・・比だが時間と比較(単位は/sec /min /hr となる) 割合・・全体と一部(同じもの)を比較(無単位) 以下参考にしてください 第13回 医療統計(Ⅱ)-比と率と割合(大阪保健医療大学 医療情報学2016) http://www.medbb.net/education/ohsumedinfo2016/#13 |
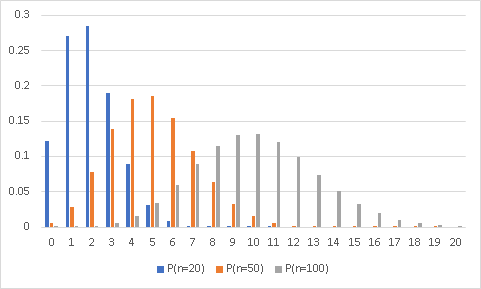
以下は例題22の症例を20人,50人,100人とした場合の発生人数の分布です.npはそれぞれ2,5,10となります.
個別確率と有意確率
教科書P131有意確率=累和された値・・・ノンパラメトリックの話を思い出してください
P137の二項分布を正規分布に近似するための連続補正 の部分も参照ください
カイ二乗分布
教科書P142χ2乗分布・・・母分散を推定できる確率分布
χ2=ΣZi2
平均からのズレの平方をとったものを足し合わせていく→偏差平方和
標準正規分布に従う独立した確率変数が1つの場合
χ2=Z12
<参考>独立した確率変数が二つの場合
χ2=Z12+Z22
カイ二乗分布表(教科書P273)
t分布と同じく自由度により確率分布は変化するカイ二乗分布(ν=1)の時のそれぞれの上側確率に相当する正規分布の確率(両側5%(片側2.5%ずつ)は全て上側に集約されてしまう
χ2=((X-μ)/σ)2
χ20.05=((1.96-0)/1)2
例)標準正規分布で有意水準両側5%の場合の境界値はz=1.96.カイ二乗分布表より優位水準上側5%の時のカイ二乗値=3.84
ピアソンのカイ二乗
カイ二乗分布の話(X-μ)を(実際に出現した度数-出現が期待される度数(期待値))に置き換え分散で除することで分子の差分を標準正規分布のN(0,1)にしていたものを,期待値で除して求めたものである.
(ポアソン分布であるとすると平均値=期待値=分散)
カイ二乗値=Σ(観察度数-期待値)2/期待値
検定
適合度の検定
P140例題28で説明1行n列
事象の起こる確率に基づく頻度(=n×p)期待値(度数))と実際に観測された度数(観察度数)の差異について検定.帰無仮説(測定した分布は想定されている分布と等しい)H0:P=(1/6,1/6,1/6,1/6,1/6,1/6)・・・サイコロの場合
独立性の検定
P146例題29で説明m行n列
こちらはそれぞれが独立しているか(関係があるか無いか)を検定
考え方は一緒
事象の起こる確率は実際に観測された度数を基に算出して全体の度数を乗じることで期待値(度数)とする.
Fisherの直接確率法
期待値が低い場合、.wilcoxonの統計量T理論分布と同様だが計算大変故に教科書では2×2表以外出てこない(考え方は一緒)
課題
1.コーヒーの好き嫌いが運動習慣に関連があるのかアンケート調査を行った.有意水準5%で検定を行え
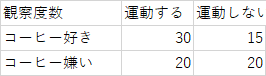
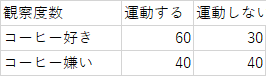
2.上記の各セルの度数を勝手に倍にしてみた.(無論現実にはやってはいけない)同様に検定を行え
補足
教科書訂正
P146例題29ですが,以下のように訂正ください.(3)有意確率と判定: の 2行目
誤)χ2=7.5<χ20.05=3.841となり
正)χ2=7.5>χ20.05=3.841となり
質問
それぞれの目が一兆回ずつ出るということもあり得る、となると思いますが実際そんなサイコロっておかしくないですか?
仰る通りで今年度の授業では取り上げる予定が無かったのですが必要だったのだなと思いながらです.(上側確率と下側確率)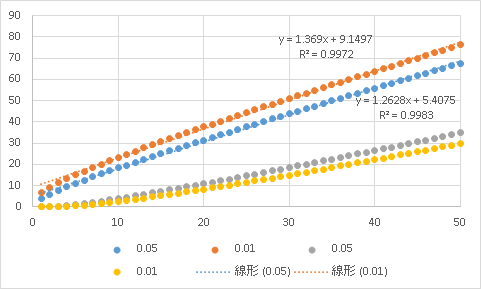
一兆回ずつ綺麗に出るサイコロってのは仰る通りおかしいという話になります.
しかしながらここでは,測定した分布と想定されている分布か否かを検定しているので,上側確率だけに注目すればよいという格好になります.
課題について
エクセルで書いている手書きじゃない,判定逆,計算よくわからん,帰無仮説,差があるとか差が無いとかそんな話ではない,計算式間違っている,H1を棄却はしない,二つの群で差があるという話ではない,4つのセルの関連があるとかないとかでもない第08回CMC 独立多群間の比較
到達目標8-1F分布とカイ二乗分布の関係を説明できる
8-2分散分析と多重検定の違いを説明できる
教科書
第5章P94-97
第8章P153-172
第10章P217-219
F分布
カイ二乗分布が偏差平方和に関する確率分布.F分布は二群の分散に関する確率分布それぞれの独立している群のカイ二乗値の比=分散の比・・・F値(FはフィッシャーのF)
U,Kはそれぞれカイ二乗分布に従う(自由度k) F(k1,k2)=U/k1/V/k2
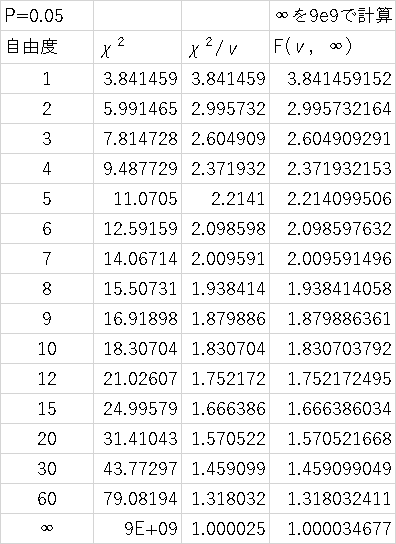
F分布とカイ二乗分布の関係
F(ν,∞)=χ^2(ν)/ν/χ^2(∞)/∞=χ^2(ν)/ν
χ^2(ν)=ν×F(ν,∞)
F分布に従う確率変数の逆数
自由度(k1,k2)を入れ替えた分布に従う例) F0.05(4,9)=6.00
1/F0.05(4,9)=F0.95(9,4)=0.1667=1/6.00)
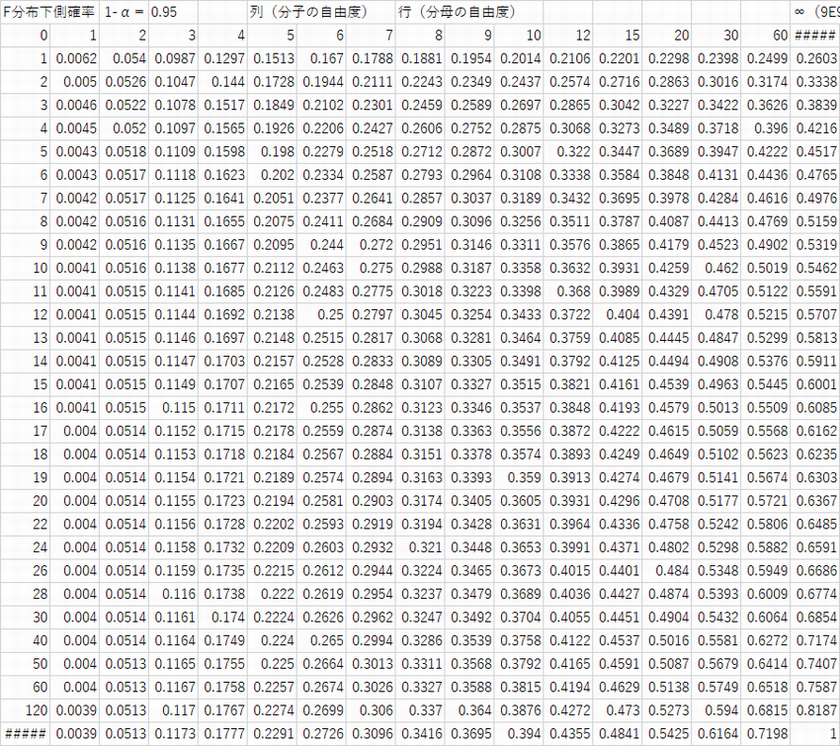
等分散の検定(F検定)(P94)
等分散性の検定・・・分散比を求めてF値より判定「2群の分散は異なるとは言えない」・・・帰無仮説を棄却できない(保留)
同時比較
全群を一括して比較一元配置分散分析(P155)
3つ以上の標本 群間分散と群内分散の分散比群間分散・・・群別の平均と群別の平均の平均で求める.自由度は群数k-1
群内分散・・・それぞれの値に対して属する群の平均を使って求める.自由度は総標本数n-群数k
群間分散と群内分散の比をとる
P158例題31
Kruskal-Wallis検定
教科書P164P166例題33のデータで極端値の話
同時比較して差があったから多重比較するというのは、何を述べたいかによるが・・・お作法的にそのように分析するケースは多々
多重検定
教科書P217ポイントとしては、それぞれの検定が独立した仮説にもとづいたものと考えて良いか否か。良いのであれば多重検定にならない
一連のものであれば対立仮説を考えたときに有意水準が5%と言いながら5%になっていないのでは?
多重に検定することでどれかあたれば帰無仮説は棄却できるので例えば3群総当たりだと有意水準0.05で多重検定(6通り)すると有意水準が0.265になってしまう。(からよくない)
有意確率補正法
Bonferriniの場合は6通り検定するのであれば、一検定あたりの有意水準だと0.05/6=0.0083となる。全体では1-(1-0.00833)^6=1-0.95103=0.0490Sidak補正の場合は同様に1-(1-0.05)^(1/6)=0.008512 1-(1-0.008512)^6=1-0.95=0.0500
多群になるほど検定あたりの有意水準が下がる→差が出にくい
多重比較法
パラメトリック法Tukey法・・・各ペアに対する平均値の差の検定
Dunnett検定・・・一つの対象群との対比
ノンパラメトリック法
Dunn法
課題
8-1)158例題31についてKruskall-Wallis検定を用いて判定せよ8-2)ある細胞を温度条件により4群にわけて培養を行いデータを測定した.標本数は,A=4,B=3,C=5,D=8であった.群間の偏差平方和SAが60 群内の偏差平方和SEが40だった場合一元配置分散分析 有意水準5%で検定せよ
8-3)曜日別に検査の管理用資料を測定した。それぞれ総当たりで二標本t検定を行った。有意確率をBonferroni補正法を用いて有意水準5%で判定し有意な組み合わせをすべて記せ
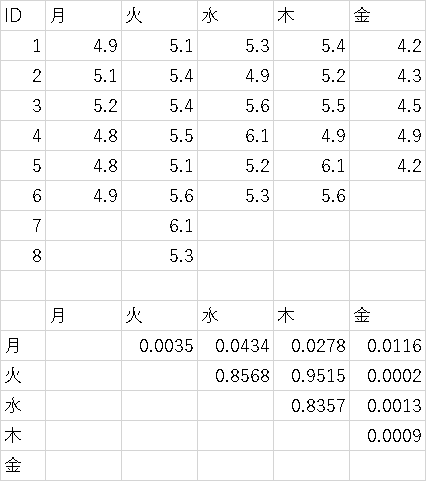
補足
課題に関するコメント
,3がよくわからん ,2が計算間違い ,1の問題を転記ミスかな(小数点はよく間違える傾向)日常生活で整数のゼロは強いが小数点は・・・ ,1の問題が違う問題をしている ,3補正しているが判定間違えている ,1判定が逆 ,2が計算間違い ,1,2計算おかしい ,2計算 ,カイ二乗分布ではなく ,3補正しているが判定間違えている ,2転記ミス? ,名無し ,3補正しているが判定間違えている ,3補正しているが判定間違えている ,1計算の間違いにもほどがある ,3補正しているが判定間違えている ,1は計算の間違いだし2は?と書いてて答えない ,1は計算間違い3もおかしい ,1計算間違い2も? ,3補正しているが判定間違えている ,2計算は正しいのに3補正しているが判定間違えている ,3補正しているが判定間違えている ,1計算間違い2計算間違い ,1計算間違い2判定間違い,3判定間違い ,1計算間違い2計算間違い ,1計算間違い判定おかしい3判定おかしい ,2間違い ,1計算違うし判定もおかしいし2計算違う,3計算おかしい ,3判定おかしい ,1計算おかしい,2もおかしい ,1)途中から謎,2)計算おかしい ,1)判定おかしい ,1)計算間違い2)判定おかしい ,3)おかしい ,1)判定おかしい2)計算おかしい ,名無し(全部あってるけど) ,2)計算間違い SA120の人が多いがなんでだろう ,3)おかしい ,1)計算間違い結果は変わらんけど ,1)計算間違い2)計算間違い ,1)判定おかしい,3)おかしい第09回CMC 相関係数・回帰直線
到達目標9-1相関係数を説明・計算することが出来る
9-2回帰直線がどのようなものか説明することが出来る
教科書P173-202
教科書のページなど確認 内容も無相関の検定や 最小二乗法の話含め手厚く書く
相関
correlative相関関係がある・・・関連がある
相関関係が無い・・・関連がない
他方の影響を受けるか受けないか
因果
cause and effect原因と結果
因果関係がある・・・影響がある
因果関係が無い・・・影響がない
普通は関連がある(相関がある)=影響を及ぼす関係(因果関係がある)と考える(考えたくなる)
例
たばこを吸う-肺がん・・・・相関関係○
コーヒーを飲む-肺がん・・・相関関係○
コーヒーと肺がんの相関関係に割り込んでいる(どちらとも相関関係がある)状態=交絡
割り込んでいるそれ=交絡因子・・・たばこ
コーヒーと肺がんに因果関係が無いとしたならその関係は疑似相関
交絡因子について
教科書P220-第3回の授業で取り上げた「真度と精度の話(誤差)」も含めて確認しておくこと
相関図
X軸とY軸に一つの対象に与えられるそれぞれの値をプロット(例:身長と体重)とりあえず図にすると関係が直感的にわかる(場合がある)
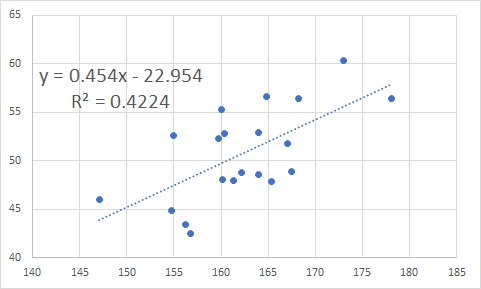
相関係数
-1から1までの値をとるXが増加すればYも増加する・・・1
Xが増加すればYは減少する・・・-1
Xが増加しようが減少しようがYは関係ない・・・0
X軸で見たときのバラツキ具合とY軸で見たときのバラツキ具合を元に計算してる
バラツキ=散布度・・・分散・・・偏差の二乗の平均
共分散=ある対象のX軸の偏差とY軸の偏差を乗じたものがベース
| Xの偏差 | Yの偏差 | 乗じた結果 |
|---|---|---|
| + | + | + |
| + | - | - |
| - | + | - |
| - | - | + |
共分散はX軸Y軸のバラツキ具合が混ざっているのでそのままの数字だと解釈しにくい→XとYの標準偏差で除する(正規化)→相関係数
単相関係数の検定
P180-回帰直線
X軸の値とY軸の値を数式(y=ax+b)で示す直線を引いたときにそれぞれの点からの差(残差)の2乗して足したもの(平方和)が最も小さい時の数式が回帰直線
決定係数
相関係数を二乗したもの数式によって説明できる割合を示す。(寄与率とも)
高ければ高いほど数式で説明出来る
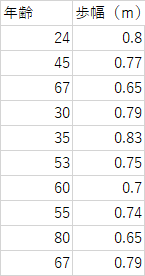
課題
以下の年齢と歩幅のデータより1)回帰直線y=a+bxを求めよ
2)相関係数rを求めよ
3)有意水準5%および1%で相関があるか検定せよ
補足
評価について(変更)
真摯に取り組んでいる方が多いのですが,一部想定しているレベルに満たない不十分な提出が増えています.違う課題を解いていたり,課題提出の際の画像が切れていたり,読みにくい文字で書いてあったり,課題を確認してもらうという意図が見えてこないものもあります.また,授業では触れていない解法(しかも間違っている)が急に出てくるケースもあり,それが複数人から出てきているケースもあります.授業に参加したうえで課題に取り組んでいないかたが一定数おられるのであれば事態は深刻です.
さらに,訂正することで課題点がもらえるということに起因しているかもしれませんが,提出にあたって十分吟味してから出さないウッカリのケースも散見されるようになってきました.
訂正についても前述のような謎理論で解かれた方もウッカリレベルのミスのようで,自力で再提出時に適切な方法による回答が送られてきます.提出時に吟味していなかった方は私の指摘により書き換えるだけです.
この方式では課題を通して誤解している部分を修正することだったのですが,残念ながら注意不足の部分を指摘するだけのものになっております.それだけ皆さんの授業外における学修が捗っているもの認識しています.
そこで,今回より課題点につきまして,ポートフォリオで△マークで示していた課題の訂正が必要な部分を指摘する方式を中止します.
訂正が必要なものについては全体告知しますので各自修正する格好でお願いします.これまでの訂正が必要なものについては,特に減点はされません
なお,課題についてシラバスで示したことを想定していないケースが散見される(講義内容に基づき取り組んだと見做せない)状況であり,シラバスや授業で示していた配点について変更させていただきます.
課題:30点→25点
試験:70点→75点
これまでの課題の訂正について(変更)
なお,1~9回までの課題の訂正は6月25日までとします.またこれまでの訂正はチャットでのやり取りとしていたのですが,上記のように特にやり取りも必要ないケースが多いことから,教務システムにPDFもしくは画像ファイルで提出してください.
記載項目としては
どの授業のものかと,氏名,学籍番号を書いてください.
一回きりですので,ケアレスミスなど無いように提出してください.
また,今回の課題提出でそれ以外のもの(再提出)を行った方がおられましたが,授業の中でも申しておりますがご遠慮いただいています.トラブルの原因になるので,改めて再提出してください.
課題に対するコメント
多くの方が訂正必要でした.(全36件)以下多いものから 1)
計算誤差かな.数値違うような
数式をきちんと書いてほしい
2)
相関係数が1を超えている
±おかしい
3)
間違っているけど なにやってるのかわからないスピアマン?
検定表が読めていない
検定の判定がおかしい
課題のこたえ
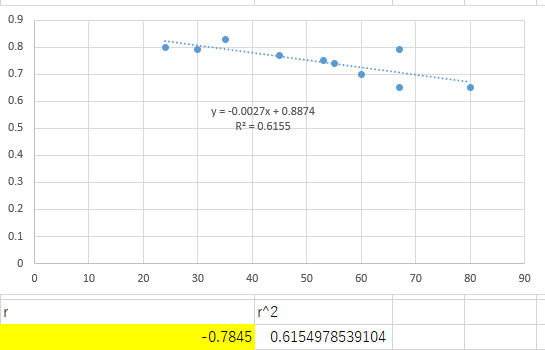
有意水準5%および1%で相関がある.
第10回CMC 多変量解析
到達目標10-1多変量解析の必要性について説明できる
10-2重回帰分析においてどのように変数が選ばれているか説明できる
多変量解析について
教科書P5多くの変量を用いて・・・探索的
予測・・・(重回帰分析)
要約・・・外的基準がない(主成分分析)
「関係ありそうなデータを集めたけどどうしたらまとまるのやら」という悩みを解決してくれるという夢を見やすい
重回帰分析
教科書P223(回帰直線の話を思い出す→単回帰分析)
回帰・・・元に戻る・・・何らか(定理や関係)に基づき戻っていく
変数ごとに有意差検定を行っても他の変数の影響が含まれてしまう
予測モデル式としての話とどのような変数が影響を与えているのか
単回帰分析
教科書P195回帰係数・・・Y=a+bXのb
決定係数・・・1に近いほど良好なモデル
重回帰分析
Y=a+b1X1+b2x2+・・・ 目的変数・・・Y説明変数・・・Xi
偏回帰係数・・・bi
標準偏回帰係数 β* 目的変数と説明変数の関係を標準化したときの偏回帰係数・・・
目的変数は量的
説明変数は量的でも質的(0,1)でも
単回帰と同じく最小二乗法で求める
決定係数・・・説明変数を増やすと値は上昇 自由度調整済み決定係数・・・1-(1-R2)(n-1)/(n-k-1) n=標本数 k=独立変数
VIF 分散拡大要因
多重共線性を見つける指標多重共線性・・・独立変数が他の独立変数と相関がある・・・偏回帰係数の標準誤差増大
VIF=(1-Ri2)-1
Ri2:他の独立変数で重回帰させたときの決定係数
許容度:1-Ri2 目安としてVIFは10以下であること=許容度が0.10を超えていること
分散分析
回帰式による変動と残差(回帰式と実測の差)の変動が異なるのか示している異なると言えなければその回帰式は統計的に・・・
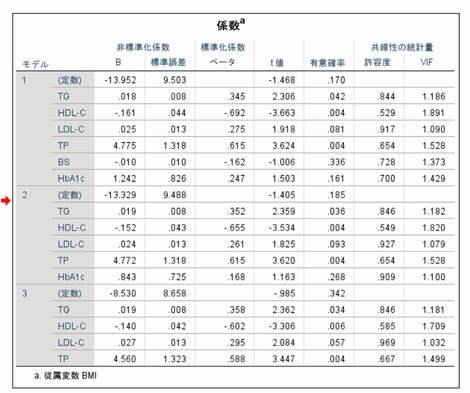
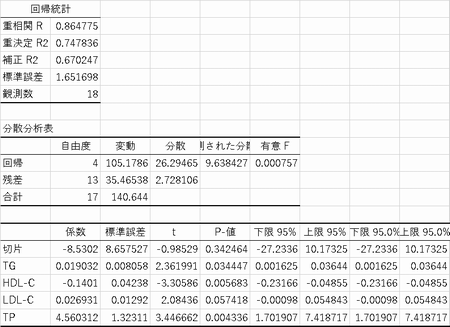
以下はSPSSの出力(データは教科書P11の「複雑な調査データ」)でBMIを従属変数 それ以外(ID 性別除く)を独立変数とした場合
変数減少法で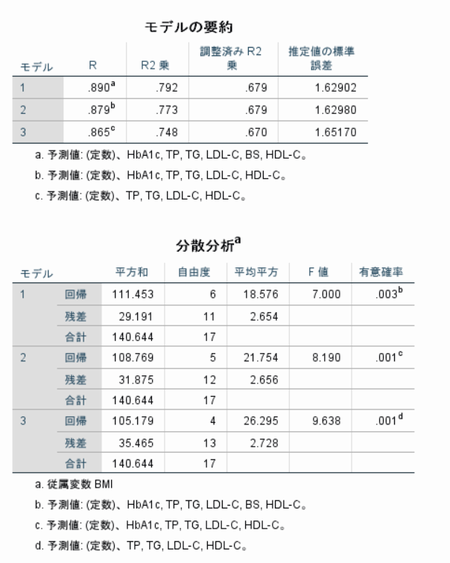
エクセルの場合(2013)
課題
以下のデータがある.授業中に示した予測式モデル(1~3)の中から測定値と一番近いモデル式を示せ.
補足
課題について
回答の集計
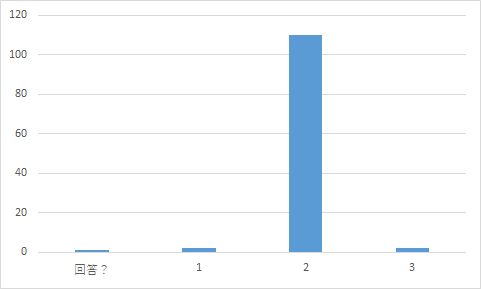
第11回CMC 相対危険
到達目標12-1相対危険を示す指標にどのようなものがあるか説明できる
12-2症例対照研究では相対危険をオッズ比で算出する理由を説明できる
この授業では相対危険=Relative Risk は一般的な用語であり、その算出指標の一つにリスク比(Risk Ratio)があるのですがそれを相対危険としているケースもあり,言葉の整理が出来ていないところでもあります。
観察研究(Observational study)
横断研究(Cross-sectional study)曝露と疾患を同時に評価
時間軸がない場合が多く(例外は性別など)因果関係までは不明になってしまいやすい
コホート研究(Cohort study)
対象に曝露している人々と非曝露群を設定、追跡調査していくスタイル
通常前向きだが、後ろ向きにみる回顧的コホート研究というのもある。(後々でも曝露群に関する情報がある場合)
症例対照研究(Case-control study)
ある状態(例えば病気に罹患している)群と、罹患していない群を設定、時間を遡って調査していくスタイル
後ろ向きにしか行えない(前向きだと曝露→疾患の順がおかしくなる)
実験的研究(介入研究)(intervention study)
コホート研究の場合、曝露群(介入群)を研究者が割り付ける → 被験者に対する倫理的配慮が肝要無作為に割り付けることが出来る場合は交絡因子を制御できる(ことが期待される)
倫理的に考えると非介入群の方が不利益になってしまう可能性が高いので、配慮した研究デザインが求められる
説明用データ
| 疾病発症 | 疾病無 | 計 | |
|---|---|---|---|
| 曝露有 | A | B | A+B |
| 曝露無 | C | D | C+D |
| 計 | A+C | B+D |
リスク比
Risk Ratio(RR)曝露(介入)の有る時と無の時の危険を示す指標の比
危険を示す指標には罹患率やら有病率やら死亡率やら
A~D:疾病発生頻度(頻度以外に罹患率やら有病率・・・)
曝露有群の発症リスク=A/(A+B)
曝露無群の発症リスク=C/(C+D)
リスク比=A/(A+B)/C/(C+D)
もし、発生頻度が低ければA+B≒B C+D≒D
リスク比≒A/B/C/D=AD/BC
オッズ比
Odds Ratio(OR)危険な事象が起きた場合と起きなかった場合の指標の比(=オッズ)について曝露(介入)の有無毎に求め比をとったもの
発症有群の曝露オッズ=A/C
発症無群の曝露オッズ=B/D
オッズ比=A/C/B/D
=AD/BC
上記のように発症頻度が低ければオッズ比とリスク比の近似値となる
課題
1)適切な相対危険を算出せよ以下はコホート研究のデータである
| 不整脈あり | 不整脈なし | 計 | |
|---|---|---|---|
| 曝露群 | 100 | 1900 | 2000 |
| 非曝露群 | 50 | 1950 | 2000 |
| 計 | 150 | 3850 | 4000 |
第12回CMC ロジスティック回帰モデル
到達目標12-1ロジット変換について説明できる
12-2ロジスティック回帰分析においてどのように変数が選ばれているか説明できる
目的変数を質的変量で重回帰分析できないのかな?という話
ロジット変換
事象の起こる確率をpとしたときその取るべき値は0~1のいずれか.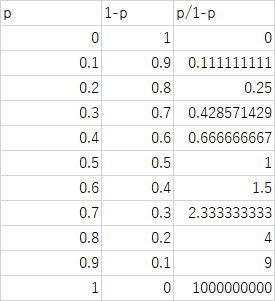
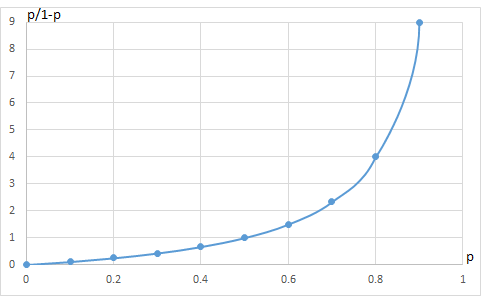
ロジット関数は,その確率の範囲を-∞~∞に拡張するもので logit(p)=ln(p)-ln(1-p)=ln(p/(1-p))で示される.
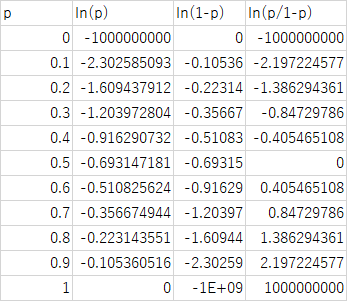
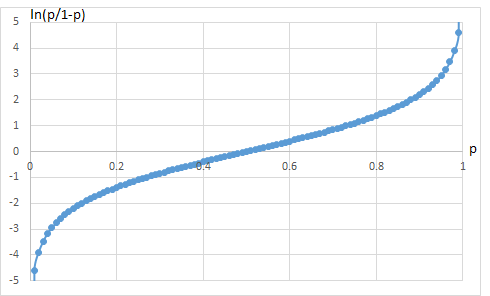
オッズを確率pで示すと
A/C=A/(A+C)/C/(A+C)=p/(1-p)
p=A/(A+C)であるが,その取りうる値は0~1.
オッズをロジット変換するとln(p)-ln(1-p)=ln(p/(1-p))
ln(p/(1-p))=a+b1X1+b2x2+・・・
ロジスティック回帰分析
画面で説明病床機能報告(厚生労働省)
https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/0000055891.html
課題
目的変数を内視鏡手術用支援機器(ダヴィンチ)の有無としたときにどのような説明変数が影響を与えているのかまとめよ授業中に示した結果に補足したものですが以下の通りです
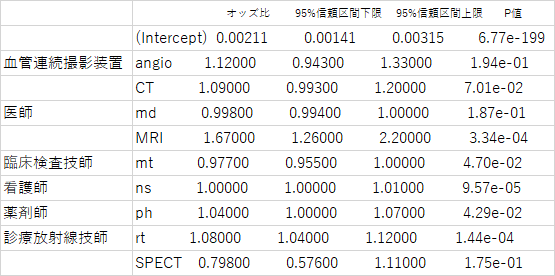
補足
統計ソフト(EZR)について
今回授業中でお示ししたもので,本来ならば皆さん授業中に実際に使っていただこうと思っていたソフトです.以下のサイトからダウンロードして,実際に試してみてください.
無料統計ソフトEZR(Easy R)(自治医科大学附属さいたま医療センター)
https://www.jichi.ac.jp/saitama-sct/SaitamaHP.files/statmed.html
授業中に示したデータについて
病床機能報告のデータより作成したデータ以下になります. 令和元年度のデータの病院-施設表より抜粋していますコチラを右クリックしてダウンロードしてください
csv形式で作成しています
課題について
課題と関係のない方を書かれている方がいます数式的には影響を受ける格好ですが実際の関係性も,直接的な影響を受けるわけではない(解釈問題)
そのことに言及している学生が数名
第13回CMC 感度・特異度・ROC曲線
到達目標13-1判別特性値の計算が出来る
13-2評価結果よりROC曲線を作成し評価やカットオフ値の検討が出来る
検査法の診断的有用性を評価する話
有病率の影響を受ける指標、受けない指標を整理しておくこと
「率」ではあるが実際には割合。時点有病率ともいう(期間有病率は時点有病率に期間中の罹患を加えたもの)
(第7回で比・率・割合の話をしましたが)
感度と特異度
教科書(P116)感度=P(陽性|D) 疾患群における真陽性の割合
偽陽性率=P(陽性|Dc) 非疾患群における偽陽性の割合
特異度=1-偽陽性率 非疾患群における真陰性の割合
予測値
有病率の影響を受ける
陽性的中率=P(D|陽性)
陰性的中率=P(Dc|陰性)
検査法の評価指標
尤度比=感度/偽陽性率
オッズ比=教科書参照 検査の有用性
AUC=ROC曲線を描いて算出 検査の分別能
何でも陽性と判断する検査は感度も偽陽性率も1になる
(なんでもかんでも、あります!! のノリ)
ROC曲線
教科書(P119)判別度の分析
感度と偽陽性率(1-特異度)を用いて曲線を描く
例題21で⑥をカットオフ値としたときの陽性的中率=7/9 陰性的中率=8/11
課題
2種類の検査法A,Bを施行したところ以下の結果を得た.AUCを求めどちらの検査が優れているか評価せよ
なおカットオフ値を12.0~15.5まで0.5刻みで設定し評価のこと
A法
| 疾患群 | 14.3 | 15.2 | 13.8 | 14.1 | 13.9 | 12.6 | 14.2 | 14.6 | 13.1 | 13.7 |
| 非疾患群 | 13.2 | 14.1 | 13.8 | 13.6 | 12.9 | 12.4 | 12.1 | 12.3 | 12.3 | 12.8 |
| 疾患群 | 14.3 | 15.2 | 13.8 | 14.1 | 13.9 | 12.6 | 14.2 | 14.6 | 13.1 | 13.7 |
| 非疾患群 | 13.2 | 14.3 | 13.8 | 12.9 | 14.4 | 14.4 | 12.1 | 15.3 | 12.3 | 12.8 |
補足
授業中に作成したエクセル
コチラを右クリックしてダウンロードしてください課題について(課題確認時の私のコメントより)
AUC1以上になっとる評価していない
AUC計算していないのに評価している(雰囲気)
名無し
これまでのおまとめ課題修正分
9回目は間違えていても大丈夫な格好にしていますので再提出全てOKではありませんでした.
×どの課題か書いていないもの
×もともと提出していないもの(修正の話なので)
×理解してもらおうと持っているのか理解できない
×該当回の全体を見直していない・・・修正が不十分
第14回 生存時間分析
到達目標14-1カプランマイヤー法による生存曲線の作成が出来る
14-2ログランク検定による生存率の差の検定を行うことが出来る
生存時間分析は治療法等の評価に時間軸を含めたもの
イベント発生までの時間による分析
生存率
生存率には計算方式が複数電算機の普及によりKaplan-Meier法でも容易に計算出来る時代
そもそも率は比の特殊な形態で単位時間あたりのイベント数を表わす
(第12回の授業で比率割合取り上げました)
Kaplan-Meierで求める非イベント発生(生存)率=1-イベント発生(死亡)率は、率では無く時点イベント(死亡)割合なので注意
<参考>
患者の生存率(地域がん登録全国協議会)
http://www.jacr.info/about/survival.html
直接法は割合。中途打ち切りがあると困る
カプランマイヤー法によるイベント発生率の計算
個票データ| 患者ID | 診断名 | 観察終了時期 | 患者ID | 診断名 | 観察終了時期 | 患者ID | 診断名 | 観察終了時期 | 患者ID | 診断名 | 観察終了時期 | 患者ID | 診断名 | 観察終了時期 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | b | 3 | 11 | a | 8 | 21 | b | 9 | 31 | b | 24+ | 41 | a | 3+ |
| 2 | b | 5 | 12 | b | 14 | 22 | b | 18 | 32 | a | 12 | 42 | b | 8 |
| 3 | b | 6 | 13 | b | 9 | 23 | a | 12+ | 33 | a | 3+ | 43 | b | 24+ |
| 4 | b | 14 | 14 | a | 1 | 24 | a | 3 | 34 | b | 13 | 44 | a | 5+ |
| 5 | a | 7+ | 15 | a | 2 | 25 | b | 17+ | 35 | b | 17 | 45 | b | 14 |
| 6 | a | 14 | 16 | a | 3 | 26 | a | 7 | 36 | a | 3 | |||
| 7 | a | 17 | 17 | a | 13 | 27 | a | 8 | 37 | b | 15 | |||
| 8 | b | 21 | 18 | b | 21 | 28 | a | 12 | 38 | b | 13 | |||
| 9 | b | 21 | 19 | b | 16 | 29 | b | 12+ | 39 | a | 21 | |||
| 10 | b | 16 | 20 | b | 24+ | 30 | a | 1 | 40 | b | 18 |
生存率の計算
疾患a| 診断からの月数 | 月開始時の生存数 | 死亡数 | 中途打ち切り数 | 死亡割合 | 生存割合 | 累積生存率 |
|---|---|---|---|---|---|---|
| 1 | 20 | 2 | 0 | 0.100 | 0.900 | 0.900 |
| 2 | 18 | 1 | 0 | 0.056 | 0.944 | 0.850 |
| 3 | 17 | 3 | 2 | 0.176 | 0.824 | 0.700 |
| 5 | 12 | 0 | 1 | 0.700 | ||
| 7 | 11 | 1 | 1 | 0.091 | 0.909 | 0.636 |
| 8 | 9 | 2 | 0 | 0.222 | 0.778 | 0.495 |
| 12 | 7 | 2 | 1 | 0.286 | 0.714 | 0.354 |
| 13 | 4 | 1 | 0 | 0.250 | 0.750 | 0.265 |
| 14 | 3 | 1 | 0 | 0.333 | 0.667 | 0.177 |
| 17 | 2 | 1 | 0 | 0.500 | 0.500 | 0.088 |
| 21 | 1 | 1 | 0 | 1.000 | 0.000 | 0.000 |
| 診断からの月数 | 月開始時の生存数 | 死亡数 | 中途打ち切り数 | 死亡割合 | 生存割合 | 累積生存率 |
|---|---|---|---|---|---|---|
| 3 | 25 | 1 | 0 | 0.040 | 0.960 | 0.960 |
| 5 | 24 | 1 | 0 | 0.042 | 0.958 | 0.920 |
| 6 | 23 | 1 | 0 | 0.043 | 0.957 | 0.880 |
| 8 | 22 | 1 | 0 | 0.045 | 0.955 | 0.840 |
| 9 | 21 | 2 | 0 | 0.095 | 0.905 | 0.760 |
| 12 | 19 | 0 | 1 | 0.760 | ||
| 13 | 18 | 2 | 0 | 0.111 | 0.889 | 0.676 |
| 14 | 16 | 3 | 0 | 0.188 | 0.813 | 0.549 |
| 15 | 13 | 1 | 0 | 0.077 | 0.923 | 0.507 |
| 16 | 12 | 2 | 0 | 0.167 | 0.833 | 0.422 |
| 17 | 10 | 1 | 1 | 0.100 | 0.900 | 0.380 |
| 18 | 8 | 2 | 0 | 0.250 | 0.750 | 0.285 |
| 21 | 6 | 3 | 0 | 0.500 | 0.500 | 0.143 |
| 24 | 3 | 0 | 3 | 0.143 |
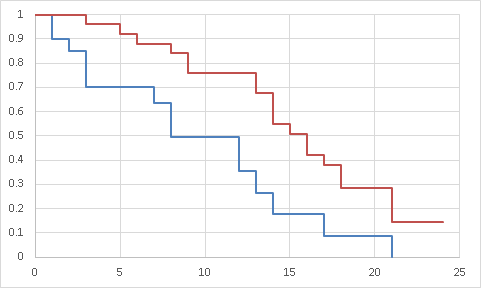
疾患a:青線
疾患b:赤線
ログランク検定
カイ二乗分布による検定を行う(期待度数と比較してバラツキがあるか否か)
イベント発生毎のクロス表(カッコ内は期待度数)
1ヶ月| 死亡数 | 生存数 | 合計 | |
| 症例a | 2(0.889) | 18(19.111) | 20 |
| 症例b | 0(1.111) | 25(24.889) | 25 |
| 合計 | 2 | 43 | 45 |
| 死亡数 | 生存数 | 合計 | |
| 症例a | 1(0.419) | 17(16.581) | 18 |
| 症例b | 0(0.581) | 25(24.419) | 25 |
| 合計 | 1 | 42 | 43 |
観察度数及び期待度数
| 診断からの月数 | a観察度数 | a打ち切り数 | a総人数 | a期待度数 | b観察度数 | b打ち切り数 | b総人数 | b期待度数 |
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 0 | 20 | 0.889 | 0 | 0 | 25 | 1.111 |
| 2 | 1 | 0 | 18 | 0.419 | 0 | 0 | 25 | 0.581 |
| 3 | 3 | 2 | 17 | 1.619 | 1 | 0 | 25 | 2.381 |
| 5 | 0 | 1 | 12 | 0.333 | 1 | 0 | 24 | 0.667 |
| 6 | 0 | 0 | 11 | 0.324 | 1 | 0 | 23 | 0.676 |
| 7 | 1 | 1 | 11 | 0.333 | 0 | 0 | 22 | 0.667 |
| 8 | 2 | 0 | 9 | 0.871 | 1 | 0 | 22 | 2.129 |
| 9 | 0 | 0 | 7 | 0.500 | 2 | 0 | 21 | 1.500 |
| 12 | 2 | 1 | 7 | 0.538 | 0 | 1 | 19 | 1.462 |
| 13 | 1 | 0 | 4 | 0.545 | 2 | 0 | 18 | 2.455 |
| 14 | 1 | 0 | 3 | 0.632 | 3 | 0 | 16 | 3.368 |
| 15 | 0 | 0 | 2 | 0.133 | 1 | 0 | 13 | 0.867 |
| 16 | 0 | 0 | 2 | 0.286 | 2 | 0 | 12 | 1.714 |
| 17 | 1 | 0 | 2 | 0.333 | 1 | 1 | 10 | 1.667 |
| 18 | 0 | 0 | 1 | 0.222 | 2 | 0 | 8 | 1.778 |
| 21 | 1 | 0 | 1 | 0.571 | 3 | 0 | 6 | 3.429 |
今回は二つの群の比較・・・自由度k=n-1=1
O1=a観察度数の総和=15
E1=a期待度数の総和=8.549
O2=b観察度数の総和=20
E2=b期待度数の総和=26.451
検定統計量χ^2=6.441
χ^2(1,0.95)=3.8415
故に帰無仮説を棄却し対立仮説を採択する(a,bの再発率に差がある)
課題
次のデータからカプランマイヤー法により生存確率を推定し生存曲線を描き,疾患ABによる違いがあるか検定せよ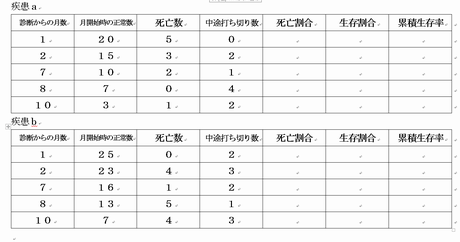
補足
課題コメント
計算間違え,途中で終わってる,表は省略しています,検定していない,生存曲線書いていない,判定逆,計算間違え,判定逆,生存曲線書いていない,判定逆第15回FTF まとめ(統計処理を行う上での注意点)
到達目標15-1授業で出た問題を全て解ける
15-2履修後も統計を自己学修する意欲を持つ